# 深度学习考试
# 2023
# 一、名词解释
# 1、残差网络(Residual Network)
解释:残差网络是一种深度神经网络结构,它通过引入“跳跃连接”(skip connections)来解决深层神经网络中的退化问题。具体来说,残差网络在每两个卷积层之间引入了一个直接的快捷连接,将输入直接加到输出上,从而形成一个残差块(Residual Block)。
作用:残差网络可以使得更深层的神经网络更容易训练,从而显著提高模型的表现。它通过让信息在前向和反向传播时绕过某些层,缓解了深度网络中的梯度消失和梯度爆炸问题。
参数和输出:残差块的输入是前一层的输出,输出是当前层的输出加上输入。
场景:主要用于图像识别、语音识别等需要深层神经网络的任务中。
# 2、Dropout
解释:Dropout是一种正则化技术,用于防止神经网络的过拟合。在训练过程中,Dropout随机“丢弃”一部分神经元及其连接,即以某一固定概率将它们的输出设为零,从而减少神经元之间的相互依赖。
作用:通过在训练过程中随机地忽略部分神经元,Dropout能够有效地减轻过拟合现象,增强模型的泛化能力。
参数:
p:丢弃的概率,通常在0.2到0.5之间。
输出:经过Dropout处理后的激活值,其中部分值被设为零。
场景:广泛用于卷积神经网络和全连接神经网络,尤其是在处理图像、文本等任务时。
# 3、批归一化(Batch Normalization)
解释:批归一化是一种用于加速神经网络训练并提高模型稳定性的技术。它在每一层网络的输出上进行归一化操作,使得输出具有零均值和单位方差。
作用:通过减少每一层输入的协方差偏移,批归一化能够加速网络的训练速度,减少对参数初始化的敏感性,并且在一定程度上起到正则化的效果。
参数:
num_features:输入特征的数量。eps:为了计算稳定性而添加的小值,通常为1e-5。momentum:用于计算运行时均值和方差的动量,默认值通常为0.1。
输出:归一化后的激活值。
场景:几乎所有的深度学习任务,包括图像分类、语音识别、自然语言处理等。
# 4、感受野(Receptive Field)
解释:感受野是指卷积神经网络中某个神经元能“看到”的输入区域的大小。也就是说,感受野是指一个神经元在前一层网络上观察到的输入区域的范围。
作用:感受野的大小决定了神经元能够捕捉到多大范围内的信息。较大的感受野可以捕捉到更多的上下文信息,对于需要全局信息的任务非常重要。
场景:感受野的概念广泛应用于卷积神经网络,尤其是在处理图像数据时。
# 5、注意力机制(Attention Mechanism)
解释:注意力机制是一种模仿人类注意力的机制,通过为不同的输入部分分配不同的权重,使模型能够更有效地关注重要的输入部分。
作用:注意力机制可以增强模型的性能,使其能够在处理序列数据(如自然语言处理)时,动态地选择对当前任务最重要的部分,从而提高模型的准确性和效率。
参数:不同的注意力机制有不同的参数,但通常包括:
query:查询向量。key:键向量。value:值向量。attention_score:用于计算注意力权重的分数。
输出:加权后的值向量。
场景:广泛用于自然语言处理任务(如机器翻译、文本摘要)以及图像处理任务(如图像描述生成)。
希望这些解释对你有所帮助!如果你有任何进一步的问题或需要更详细的解释,请告诉我。
# 二、简答题
# 1. 请列出卷积神经网络的主要结构模块,并简述各个模块的功能(6分)
卷积神经网络(CNN)的主要结构模块:
卷积层(Convolutional Layer):
- 功能:应用卷积核(filters)在输入特征图上进行滑动窗口操作,从而提取局部特征。每个卷积核会生成一个特征图,多个卷积核可以捕捉不同的特征。
- 参数:卷积核大小(如3x3、5x5)、步长(stride)、填充(padding)。
- 输出:特征图,表示输入图像的局部特征。
激活层(Activation Layer):
- 功能:引入非线性,使得神经网络可以拟合复杂的函数。常用的激活函数有ReLU(Rectified Linear Unit)、Sigmoid、Tanh等。
- 参数:激活函数类型。
- 输出:非线性变换后的特征图。
池化层(Pooling Layer):
- 功能:对特征图进行下采样,减少特征图的尺寸,同时保留重要特征。常用的方法有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 参数:池化窗口大小、步长。
- 输出:下采样后的特征图。
全连接层(Fully Connected Layer):
- 功能:将卷积层和池化层提取到的特征进行综合,通过线性变换和激活函数进行特征融合,常用于最后的分类任务。
- 参数:输入神经元数,输出神经元数。
- 输出:分类结果或回归值。
归一化层(Normalization Layer):
- 功能:批归一化(Batch Normalization)或层归一化(Layer Normalization),用于加速训练过程,提高模型稳定性。
- 参数:归一化类型及相应的超参数。
- 输出:归一化后的特征图。
Dropout层:
- 功能:在训练过程中随机丢弃部分神经元,防止过拟合。
- 参数:丢弃概率(p)。
- 输出:部分神经元被丢弃的特征图。
# 2. 请简述生成对抗网络的基本架构和训练过程(7分)(ppt - 0.6)
生成对抗网络(GAN)的基本架构:
生成器(Generator):
- 功能:接受一个随机噪声向量作为输入,生成逼真的数据(如图像)。
- 结构:通常是一个反卷积神经网络(Transposed Convolutional Network)。
判别器(Discriminator):
- 功能:判断输入数据是真实的还是生成的。
- 结构:通常是一个卷积神经网络(Convolutional Neural Network)。
训练过程:
初始化:随机初始化生成器和判别器的参数。
生成器训练:
- 从随机噪声分布中采样生成输入噪声。
- 使用生成器生成假数据。
- 将假数据输入判别器,得到预测结果。
- 计算生成器损失:通过反向传播调整生成器参数,使得生成的数据更逼真(判别器更难以区分真假)。
判别器训练:
- 从真实数据分布中采样真实数据。
- 使用生成器生成假数据。
- 将真实数据和假数据分别输入判别器,得到预测结果。
- 计算判别器损失:通过反向传播调整判别器参数,使其能够更准确地区分真实数据和假数据。
交替训练:
- 交替进行生成器和判别器的训练,通常训练一次生成器,训练一次判别器,反复进行多次迭代,直到生成的数据足够逼真,判别器难以区分真假数据。
损失函数:
- 生成器损失:使用交叉熵损失,使生成器生成的数据尽可能逼真。
- 判别器损失:使用交叉熵损失,使判别器能够准确区分真实数据和生成数据。
# 3. 请简述R-CNN (R-CNN, Fast RCNN, Faster-RCNN)系列工作的改进思路(7分)
R-CNN系列工作及其改进思路:
R-CNN(Regions with Convolutional Neural Network features):
- 思路:首先使用选择性搜索(Selective Search)算法生成候选区域(Region Proposals),然后将这些区域分别输入到卷积神经网络中提取特征,最后使用SVM进行分类,并使用回归器进行边界框调整。
- 优点:在目标检测任务上取得了显著的性能提升。
- 缺点:计算效率低,因为每个候选区域都要单独进行特征提取,且存储和训练开销大。
Fast R-CNN:
- 思路:对R-CNN进行改进,通过将整个图像输入卷积神经网络一次性提取特征,然后对这些特征进行ROI(Region of Interest)池化,将不同大小的候选区域映射到固定大小的特征图上,再进行分类和边界框回归。
- 优点:显著提高了计算效率,因为卷积操作只进行一次,且可以在训练过程中同时优化分类和边界框回归。
- 缺点:仍需借助外部的候选区域生成算法(如选择性搜索),该步骤较慢。
Faster R-CNN:
- 思路:进一步改进Fast R-CNN,通过引入区域建议网络(Region Proposal Network,RPN)来替代外部的候选区域生成算法。RPN在特征图上滑动窗口,生成候选区域,并同时进行分类和边界框回归。
- 优点:实现了候选区域生成和特征提取的端到端训练,极大地提高了计算效率,并且整体框架更加简洁高效。
- 缺点:相比于前两个版本,Faster R-CNN的实现更加复杂,训练过程需要更多的计算资源。
这些改进逐步解决了R-CNN在效率和端到端训练上的问题,使得R-CNN系列模型在目标检测任务中取得了广泛应用。
# 三、计算题
# 计算same-卷积

import numpy as np
# 输入矩阵
input_matrix = np.array([
[5, 6, 0, 1, 8, 2],
[2, 5, 7, 2, 3, 7],
[0, 7, 2, 4, 5, 6],
[5, 3, 6, 9, 3, 1],
[6, 5, 3, 1, 4, 6],
[5, 2, 4, 0, 8, 7]
])
# 卷积核
kernel1 = np.array([
[1, -1, 0],
[-1, 1, -1],
[0, -1, 1]
])
kernel2 = np.array([
[-1, 2, -1],
[1, 5, 1],
[-1, 0, -1]
])
# 卷积步长
stride = 1
# Same 卷积
pad_size = kernel1.shape[0] // 2
padded_input = np.pad(input_matrix, ((pad_size, pad_size), (pad_size, pad_size)), mode='constant')
def conv2d(input_matrix, kernel, stride):
kernel_height, kernel_width = kernel.shape
input_height, input_width = input_matrix.shape
output_height = (input_height - kernel_height) // stride + 1
output_width = (input_width - kernel_width) // stride + 1
output_matrix = np.zeros((output_height, output_width))
for i in range(0, output_height):
for j in range(0, output_width):
region = input_matrix[i*stride:i*stride+kernel_height, j*stride:j*stride+kernel_width]
output_matrix[i, j] = np.sum(region * kernel)
return output_matrix
# 计算特征图
feature_map1 = conv2d(padded_input, kernel1, stride)
feature_map2 = conv2d(padded_input, kernel2, stride)
# 激活函数ReLU
relu = lambda x: np.maximum(0, x)
feature_map1 = relu(feature_map1)
feature_map2 = relu(feature_map2)
feature_map1, feature_map2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
Result: run success✅
(array([[2., 3., 0., 0., 9., 0.],
[0., 0., 8., 0., 0., 4.],
[0., 5., 0., 0., 0., 0.],
[1., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 2., 0.],
[0., 0., 4., 0., 0., 0.]]),
array([[26., 26., 0., 3., 34., 15.],
[12., 39., 24., 7., 27., 29.],
[ 3., 27., 16., 12., 22., 43.],
[16., 29., 29., 48., 18., 11.],
[40., 20., 19., 9., 16., 25.],
[34., 20., 22., 7., 48., 51.]]))
2
3
4
5
6
7
8
9
10
11
12
输入矩阵与卷积核
输入矩阵: $$ \begin{bmatrix} 5 & 6 & 0 & 1 & 8 & 2 \ 2 & 5 & 7 & 2 & 3 & 7 \ 0 & 7 & 2 & 4 & 5 & 6 \ 5 & 3 & 6 & 9 & 3 & 1 \ 6 & 5 & 3 & 1 & 4 & 6 \ 5 & 2 & 4 & 0 & 8 & 7 \end{bmatrix} $$ 卷积核1: $$ \begin{bmatrix} 1 & -1 & 0 \ -1 & 1 & -1 \ 0 & -1 & 1 \end{bmatrix} $$ 卷积核2: $$ \begin{bmatrix} -1 & 2 & -1 \ 1 & 5 & 1 \ -1 & 0 & -1 \end{bmatrix} $$
计算特征图
使用 same 卷积方式和 ReLU 激活函数,得到的特征图如下:
特征图1: $$ \begin{bmatrix} 2 & 3 & 0 & 0 & 9 & 0 \ 0 & 0 & 8 & 0 & 0 & 4 \ 0 & 5 & 0 & 0 & 0 & 0 \ 1 & 0 & 0 & 1 & 0 & 0 \ 0 & 0 & 0 & 0 & 2 & 0 \ 0 & 0 & 4 & 0 & 0 & 0 \end{bmatrix} $$ 特征图2: $$ \begin{bmatrix} 26 & 26 & 0 & 3 & 34 & 15 \ 12 & 39 & 24 & 7 & 27 & 29 \ 3 & 27 & 16 & 12 & 22 & 43 \ 16 & 29 & 29 & 48 & 18 & 11 \ 40 & 20 & 19 & 9 & 16 & 25 \ 34 & 20 & 22 & 7 & 48 & 51 \end{bmatrix} $$ 以上是根据给定的输入矩阵和卷积核计算得到的特征图,并经过 ReLU 激活函数处理后的结果。
# Same 卷积后的填充输入矩阵
填充后的输入矩阵: $$ \begin{bmatrix} 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ 0 & 5 & 6 & 0 & 1 & 8 & 2 & 0 \ 0 & 2 & 5 & 7 & 2 & 3 & 7 & 0 \ 0 & 0 & 7 & 2 & 4 & 5 & 6 & 0 \ 0 & 5 & 3 & 6 & 9 & 3 & 1 & 0 \ 0 & 6 & 5 & 3 & 1 & 4 & 6 & 0 \ 0 & 5 & 2 & 4 & 0 & 8 & 7 & 0 \ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \end{bmatrix} $$
# 计算特征图1第一行第一列的值
我们取填充后的输入矩阵中对应的3x3区域和卷积核1相乘并求和: $$ \begin{bmatrix} 0 & 0 & 0 \ 0 & 5 & 6 \ 0 & 2 & 5 \end{bmatrix} $$ 与卷积核1: $$ \begin{bmatrix} 1 & -1 & 0 \ -1 & 1 & -1 \ 0 & -1 & 1 \end{bmatrix} $$ 相乘并求和: $$ (0 \cdot 1) + (0 \cdot -1) + (0 \cdot 0) + (0 \cdot -1) + (5 \cdot 1) + (6 \cdot -1) + (0 \cdot 0) + (2 \cdot -1) + (5 \cdot 1) = 0 + 0 + 0 + 0 + 5 - 6 + 0 - 2 + 5 = 2 $$ 经过ReLU激活函数: $$ \text{ReLU}(2) = 2 $$ 所以,特征图1第一行第一列的值为 2。

# 计算模型 A 和 B 的交叉熵损失
输入和期望输出:
期望输出:(0,0,0,1)
模型 A 的实际输出:(\ln20, \ln40, \ln60, \ln80)
模型 B 的实际输出:(\ln10, \ln30, \ln50, \ln90)
我们需要先对这两个输出分别应用 softmax 进行归一化,然后计算交叉熵损失。
# 1. 计算模型 A 的 softmax 输出
首先计算模型 A 的 softmax:
$$ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $$
其中 (x_i = (\ln20, \ln40, \ln60, \ln80))。
计算每个分量的指数:
$$ e^{\ln20} = 20, \quad e^{\ln40} = 40, \quad e^{\ln60} = 60, \quad e^{\ln80} = 80 $$
求和:
$$ 20 + 40 + 60 + 80 = 200 $$
然后计算 softmax 输出:
$$ \text{softmax}(\ln20) = \frac{20}{200} = 0.1 $$
$$ \text{softmax}(\ln40) = \frac{40}{200} = 0.2 $$
$$ \text{softmax}(\ln60) = \frac{60}{200} = 0.3 $$
$$ \text{softmax}(\ln80) = \frac{80}{200} = 0.4 $$
# 2. 计算模型 B 的 softmax 输出
类似地,计算模型 B 的 softmax:
$$ x_i = (\ln10, \ln30, \ln50, \ln90) $$
计算每个分量的指数:
$$ e^{\ln10} = 10, \quad e^{\ln30} = 30, \quad e^{\ln50} = 50, \quad e^{\ln90} = 90 $$
求和:
$$ 10 + 30 + 50 + 90 = 180 $$
然后计算 softmax 输出:
$$ \text{softmax}(\ln10) = \frac{10}{180} \approx 0.0556 $$
$$ \text{softmax}(\ln30) = \frac{30}{180} \approx 0.1667 $$
$$ \text{softmax}(\ln50) = \frac{50}{180} \approx 0.2778 $$
$$ \text{softmax}(\ln90) = \frac{90}{180} = 0.5 $$
# 3. 计算交叉熵损失
交叉熵损失的计算公式为:
$$ L = -\sum_{i=1}^{n} y_i \log(p_i) $$
对于期望输出 $(0,0,0,1)$,只考虑第四个分量:
- 模型 A 的交叉熵损失:
$$ L_A = -1 \cdot \log(0.4) = -\log(0.4) $$
使用给定的对数提示:
$$ \log(2) = 0.301, \quad \log(3) = 0.477 $$
由于 (0.4 = $\frac{2}{5}$),我们可以用对数规则计算:
$$ \log(0.4) = \log\left(\frac{2}{5}\right) = \log(2) - \log(5) = 0.301 - \log(5) $$
其中:
$$ \log(5) = \log\left(\frac{10}{2}\right) = \log(10) - \log(2) = 1 - 0.301 = 0.699 $$
因此:
$$ \log(0.4) = 0.301 - 0.699 = -0.398 $$
所以,模型 A 的交叉熵损失:
$$ L_A = -(-0.398) = 0.398 $$
- 模型 B 的交叉熵损失:
$$ L_B = -1 \cdot \log(0.5) = -\log(0.5) $$
由于 (0.5 = \frac{1}{2}),我们可以用对数规则计算:
$$ \log(0.5) = \log\left(\frac{1}{2}\right) = \log(1) - \log(2) = 0 - 0.301 = -0.301 $$
所以,模型 B 的交叉熵损失:
$$ L_B = -(-0.301) = 0.301 $$
# 4. 比较模型 A 和 B 的损失
模型 A 的交叉熵损失:0.398
模型 B 的交叉熵损失:0.301
由于交叉熵损失越小越好,因此模型 B 更好。
# 四、设计题

# 图像描述模型设计方案
图像描述(Image Captioning)模型的目标是生成描述输入图像的自然语言句子。以下是一个包含新思路和观点的图像描述模型设计方案:
# 一. 模型架构概述
图像特征提取模块:
- 使用卷积神经网络(CNN)如ResNet或EfficientNet,从输入图像中提取高层次特征。
- 新思路:在特征提取阶段引入多尺度特征融合,使用特征金字塔网络(FPN)或BiFPN,以捕获不同尺度的图像信息,从而更好地描述复杂场景。
注意力机制(Attention Mechanism):
- 使用注意力机制(例如,Bahdanau或Luong Attention),使模型在生成描述时能聚焦于图像的不同部分。
- 新观点:采用多头自注意力机制(如Transformer中的Multi-Head Attention),以同时关注图像的不同区域,提高生成描述的多样性和准确性。
序列生成模块:
- 使用循环神经网络(RNN)或长短期记忆网络(LSTM),结合前述注意力机制,根据提取的图像特征生成描述性文本。
- 新思路:利用Transformer架构(如BERT或GPT),代替传统的RNN/LSTM,从而提高文本生成的质量和并行处理能力。
多模态融合:
- 将视觉特征和文本特征在生成过程中进行融合,保证生成的句子与图像内容高度一致。
- 新观点:引入跨模态注意力机制(Cross-Modal Attention),在文本生成过程中,动态调整图像和文本特征的权重,提升描述的精确性。
# 二. 详细设计
图像特征提取模块:
- 使用预训练的ResNet50作为基础特征提取器,获取图像的特征图。
- 在特征提取的基础上,使用FPN融合多尺度特征,以获取丰富的图像信息。
多头自注意力机制:
- 将提取的图像特征通过线性变换,生成多头自注意力机制所需的Query、Key和Value。
- 通过多头自注意力机制,计算每个位置的注意力权重,并加权求和得到最终特征表示。
Transformer架构:
- 使用Encoder-Decoder架构的Transformer模型,Encoder部分处理图像特征,Decoder部分生成文本描述。
- Encoder部分包括多层多头自注意力和前馈神经网络,捕获图像的全局特征。
- Decoder部分使用多头自注意力机制,同时处理先前生成的文本和图像特征,实现图像和文本特征的融合。
跨模态注意力机制:
- 在Decoder部分,加入跨模态注意力层,使用图像特征作为Query,文本特征作为Key和Value,动态调整注意力权重。
- 通过这种方式,在每一步生成文本时,模型能够灵活调整对图像和先前文本的关注,确保生成的描述与图像内容高度一致。
# 三. 新思路和新观点的优势
- 多尺度特征融合:通过FPN或BiFPN,模型能够更好地捕捉图像中不同尺度的信息,增强对复杂场景的描述能力。
- 多头自注意力机制:提高模型在生成描述时的灵活性和准确性,生成的文本更加多样化和符合图像内容。
- Transformer架构:提升文本生成的并行处理能力,减少训练时间,提高描述质量。
- 跨模态注意力机制:增强图像和文本特征的融合,确保生成的描述更加精确和连贯。
# 核心代码实现
以下是使用PyTorch实现的图像描述模型,包括核心模块和详细注释。
import torch
import torch.nn as nn
import torchvision.models as models
from transformers import BertTokenizer, BertModel
# 图像特征提取模块
class ImageFeatureExtractor(nn.Module):
def __init__(self):
super(ImageFeatureExtractor, self).__init__()
resnet = models.resnet50(pretrained=True)
modules = list(resnet.children())[:-2] # 去除最后的全连接层
self.resnet = nn.Sequential(*modules)
self.fpn = FPN() # FPN层
def forward(self, x):
features = self.resnet(x)
fpn_features = self.fpn(features) # 多尺度特征融合
return fpn_features
# 多尺度特征融合模块 (FPN)
class FPN(nn.Module):
def __init__(self):
super(FPN, self).__init__()
# FPN 实现代码
# 这里简化为示意,实际实现需要更多细节
self.conv1 = nn.Conv2d(2048, 256, kernel_size=1)
def forward(self, x):
x = self.conv1(x)
return x
# 多头自注意力机制模块
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadSelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, embed_size, bias=False)
self.keys = nn.Linear(self.head_dim, embed_size, bias=False)
self.queries = nn.Linear(self.head_dim, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
query = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(query)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.embed_size
)
out = self.fc_out(out)
return out
# Transformer编码器-解码器架构
class Transformer(nn.Module):
def __init__(self, embed_size, heads, num_layers, forward_expansion, dropout, vocab_size, max_length):
super(Transformer, self).__init__()
self.encoder = nn.ModuleList(
[nn.TransformerEncoderLayer(embed_size, heads, forward_expansion, dropout) for _ in range(num_layers)]
)
self.decoder = nn.ModuleList(
[nn.TransformerDecoderLayer(embed_size, heads, forward_expansion, dropout) for _ in range(num_layers)]
)
self.src_word_embedding = nn.Embedding(vocab_size, embed_size)
self.src_position_embedding = nn.Embedding(max_length, embed_size)
self.trg_word_embedding = nn.Embedding(vocab_size, embed_size)
self.trg_position_embedding = nn.Embedding(max_length, embed_size)
self.dropout = nn.Dropout(dropout)
self.fc_out = nn.Linear(embed_size, vocab_size)
self.embed_size = embed_size
self.scale = torch.sqrt(torch.FloatTensor([embed_size]))
def make_src_mask(self, src):
src_mask = src.transpose(0, 1) == 0
return src_mask.to(src.device)
def make_trg_mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
return trg_mask.to(trg.device)
def forward(self, src, trg):
N, seq_length = src.shape
src_positions = (
torch.arange(0, seq_length)
.unsqueeze(0)
.expand(N, seq_length)
.to(src.device)
)
embed_src = self.dropout(
(self.src_word_embedding(src) + self.src_position_embedding(src_positions))
* self.scale
)
trg_positions = (
torch.arange(0, trg.shape[1])
.unsqueeze(0)
.expand(N, trg.shape[1])
.to(trg.device)
)
embed_trg = self.dropout(
(self.trg_word_embedding(trg) + self.trg_position_embedding(trg_positions))
* self.scale
)
src_padding_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
for layer in self.encoder:
embed_src = layer(embed_src, src_key_padding_mask=src_padding_mask)
out = embed_trg
for layer in self.decoder:
out = layer(out, embed_src, tgt_mask=trg_mask, memory_key_padding_mask=src_padding_mask)
out = self.fc_out(out)
return out
# 跨模态注意力机制模块
class CrossModalAttention(nn.Module):
def __init__(self, embed_size):
super(CrossModalAttention, self).__init__()
self.attention = nn.MultiheadAttention(embed_size, num_heads=8)
def forward(self, text_features, image_features):
attention_output, _ = self.attention(text_features, image_features, image_features)
return attention_output
# 创建图像描述模型
class ImageCaptioningModel(nn.Module):
def __init__(self, vocab_size, embed_size=512, num_layers=6, heads=8, forward_expansion=2048, dropout=0.1, max_length=100):
super(ImageCaptioningModel, self).__init__()
self.image_feature_extractor = ImageFeatureExtractor()
self.multi_head_attention = MultiHeadSelfAttention(embed_size, heads)
self.transformer = Transformer(embed_size, heads, num_layers, forward_expansion, dropout, vocab_size, max_length)
self.cross_modal_attention = CrossModalAttention(embed_size)
self.fc = nn.Linear(embed_size, vocab_size)
def forward(self, images, captions):
image_features = self.image_feature_extractor(images)
multi_head_attention_output = self.multi_head_attention(image_features, image_features, image_features, None)
transformer_output = self.transformer(captions, captions)
cross_modal_attention_output = self.cross_modal_attention(transformer_output, multi_head_attention_output)
outputs = self.fc(cross_modal_attention_output)
return outputs
# 超参数定义
input_shape = (3, 224, 224) # 输入图像形状 (C, H, W)
vocab_size = 10000 # 词汇表大小
# 创建图像描述模型实例
model = ImageCaptioningModel(vocab_size)
# 打印模型结构
print(model)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
这段代码展示了一个基于PyTorch的图像描述模型,包括图像特征提取、多头自注意力机制、Transformer架构和跨模态注意力机制的详细实现和注释。模型通过多尺度特征融合和跨模态注意力机制,提高了生成描述的精确性和连贯性。
# 2023
# 一、名词解释
深度信念网络,胶囊网络,深度可分离卷积,目标检测,焦点损失(Focal loss)
# 1、深度信念网络(Deep Belief Network):
- 深度信念网络是一种深度学习模型,由多层受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)组成。
- RBM是一种基于能量的概率模型,用于学习数据的分布和特征表示。深度信念网络通过逐层训练,逐步提取数据的高层抽象特征。
# 2、胶囊网络(Capsule Network):
- 胶囊网络是一种神经网络结构,旨在克服传统卷积神经网络(CNN)对姿态变化和空间关系的不适应性。
- 胶囊网络引入胶囊单元(Capsule),每个胶囊单元表示一个特定的实体实例,并且存储了该实体的属性和姿态信息。
- 相比于传统CNN,胶囊网络在处理图像中的对象变换和关系建模方面具有更强的表达能力。
# 3、深度可分离卷积(Depthwise Separable Convolution):
- 深度可分离卷积是一种卷积操作,将卷积分解为深度卷积和逐点卷积两个步骤进行。
- 首先,深度卷积对每个输入通道进行卷积操作,产生中间特征图;然后,逐点卷积对中间特征图进行逐点线性组合得到最终输出。
- 深度可分离卷积能够在减少参数量的同时保持模型的表达能力,常用于轻量级模型设计和移动端应用。
# 4、目标检测(Object Detection):
- 目标检测是计算机视觉领域的重要任务,旨在从图像或视频中检测和定位图像中的特定目标对象。
- 目标检测任务通常包括两个子任务:目标定位(Localization)和目标分类(Classification),即找到目标在图像中的位置并确定其类别。
- 目标检测应用广泛,包括自动驾驶、视频监控、医学图像分析等领域。
# 5、焦点损失(Focal Loss):
- 焦点损失是一种用于解决类别不平衡问题的损失函数,特别适用于目标检测任务。
- 焦点损失通过调整难以分类样本的权重,降低易分类样本的影响,从而加强模型对难以分类样本的学习。
- 焦点损失函数的设计使得模型更加关注于重要的样本,从而提高了模型在类别不平衡情况下的性能。
以上是对深度信念网络、胶囊网络、深度可分离卷积、目标检测和焦点损失的简要解释。
# 二、简答题
# 请写出对矩阵Amxn(m≠n)进行奇异值分解的过程。
矩阵 ( A_{$m \times n$} ) 的奇异值分解(SVD)
奇异值分解是一种将矩阵分解为三个矩阵乘积的技术,用于分析矩阵的结构和特性。对于一个 ( $m \times n$ ) 的矩阵 ( A )(其中 ( $m \neq n$ )),其奇异值分解过程如下:
定义奇异值分解:对于矩阵 ( A ),可以分解为三个矩阵的乘积: $$ A = U \Sigma V^T $$ 其中:
- ( U ) 是一个 ( $m \times m$ ) 的正交矩阵。
- ( $\Sigma$ ) 是一个 ( $m \times n$ ) 的对角矩阵,其对角线上是 ( A ) 的奇异值。
- ( V ) 是一个 ( $n \times n$ ) 的正交矩阵。
计算步骤:
- 计算 ( A^T A ) 的特征值和特征向量,得到 ( V )。
- 计算 ( A A^T ) 的特征值和特征向量,得到 ( U )。
- 奇异值 ( $\sigma_i$ ) 是 ( A^T A ) 或 ( A A^T ) 的特征值的平方根,排列在 ( $\Sigma$ ) 的对角线上。
图示说明:
A (m x n) = U (m x m) * Σ (m x n) * V^T (n x n)
详细步骤:
计算 ( A^T A ) 和 ( A A^T ):
- ( A^T A ) 是一个 ( $n \times n$ ) 的矩阵。
- ( A A^T ) 是一个 ( $m \times m$ ) 的矩阵。
特征分解:
- 对 ( A^T A ) 进行特征分解:$$ A^T A = V \Lambda V^T $$,其中 ( $\Lambda$ ) 是特征值对角矩阵,( V ) 是特征向量矩阵。
- 对 ( A A^T ) 进行特征分解:$$ A A^T = U \Gamma U^T $$,其中 ( $\Gamma$ ) 是特征值对角矩阵,( U ) 是特征向量矩阵。
奇异值计算:
- 奇异值 ( $\sigma_i$ ) 是 ( $\Lambda$ ) 和 ( $\Gamma$ ) 的特征值的平方根,即:$$ \sigma_i = \sqrt{\lambda_i} $$ 或 $$ \sigma_i = \sqrt{\gamma_i} $$。
构建 ( $\Sigma$ ):
- 构建对角矩阵 ( $\Sigma$ ),将奇异值 ( $\sigma_i$ ) 排列在对角线上。
最终分解:
- 将 ( U ),( $\Sigma$ ) 和 ( V ) 组合,得到奇异值分解:$$ A = U \Sigma V^T $$。
这样,我们就完成了对矩阵 ( A ) 的奇异值分解。通过这种分解方式,可以获得矩阵的奇异值以及对应的奇异向量,从而进一步分析矩阵的性质和特征。
# 请图示说明卷积神经网络的主要组成部分及其功能。(ppt - 0.3C3)
卷积神经网络(CNN)的主要组成部分及其功能
卷积神经网络(CNN)是一种专门用于处理网格数据(如图像)的深度学习模型。它的主要组成部分及其功能如下:
卷积层(Convolutional Layer):
功能:提取图像的局部特征。
操作:通过卷积核(滤波器)对输入进行卷积操作,生成特征图。
图示:
输入图像 -> [卷积核] -> 特征图1
激活层(Activation Layer):
功能:引入非线性。
常用激活函数:ReLU(Rectified Linear Unit),输出为输入的正部分,负部分置零。
图示:
特征图 -> [ReLU] -> 激活后的特征图1
池化层(Pooling Layer):
- 功能:降维和减小计算量。
- 操作:通过最大池化或平均池化对特征图进行下采样。
- 图示:
激活后的特征图 -> [池化] -> 下采样后的特征图1
全连接层(Fully Connected Layer):
功能:综合特征进行分类或回归。
操作:将特征图展开为向量并与权重矩阵相乘,输出类别概率或数值。
图示:
展开后的特征 -> [全连接层] -> 输出1
卷积神经网络结构图示
以下是一个简单的卷积神经网络的结构示意图:
输入图像 -> [卷积层] -> [激活层] -> [池化层] -> [卷积层] -> [激活层] -> [池化层] -> [全连接层] -> 输出
输入图像:假设输入图像大小为 (32 \times 32 \times 3)(宽 (\times) 高 (\times) 通道数)。
卷积层1:
- 卷积核大小:(3 \times 3)
- 卷积核个数:32
- 输出特征图大小:(32 \times 32 \times 32)
激活层1:ReLU
池化层1:
- 池化方式:最大池化
- 池化窗口大小:(2 \times 2)
- 下采样后特征图大小:(16 \times 16 \times 32)
卷积层2:
- 卷积核大小:(3 \times 3)
- 卷积核个数:64
- 输出特征图大小:(16 \times 16 \times 64)
激活层2:ReLU
池化层2:
- 池化方式:最大池化
- 池化窗口大小:(2 \times 2)
- 下采样后特征图大小:(8 \times 8 \times 64)
全连接层:
- 输入:展开后的向量大小 (8 \times 8 \times 64 = 4096)
- 输出:例如10个类别的概率
输出层:
- 输出类别的概率分布或回归值
图示说明
输入图像 (32x32x3)
|
v
[卷积层1] (3x3 卷积核, 32个) -> [激活层1] (ReLU) -> [池化层1] (2x2 最大池化)
| |
v v
特征图 (32x32x32) 下采样特征图 (16x16x32)
|
v
[卷积层2] (3x3 卷积核, 64个) -> [激活层2] (ReLU) -> [池化层2] (2x2 最大池化)
| |
v v
特征图 (16x16x64) 下采样特征图 (8x8x64)
|
v
展开为向量 (4096) -> [全连接层] -> 输出 (10个类别)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 请给出GRU的主要思想,并用图和公式说明。(PPt - 0.4)
GRU(门控循环单元)的主要思想
GRU(Gated Recurrent Unit)是一种改进的循环神经网络(RNN),旨在解决传统RNN在处理长序列时存在的梯度消失和梯度爆炸问题。GRU通过引入门控机制,有效地控制信息流,从而捕捉长时间依赖关系。
GRU的主要组成部分包括:
- 更新门(Update Gate)
- 重置门(Reset Gate)
- 新信息候选(Candidate Activation)
GRU的结构和公式
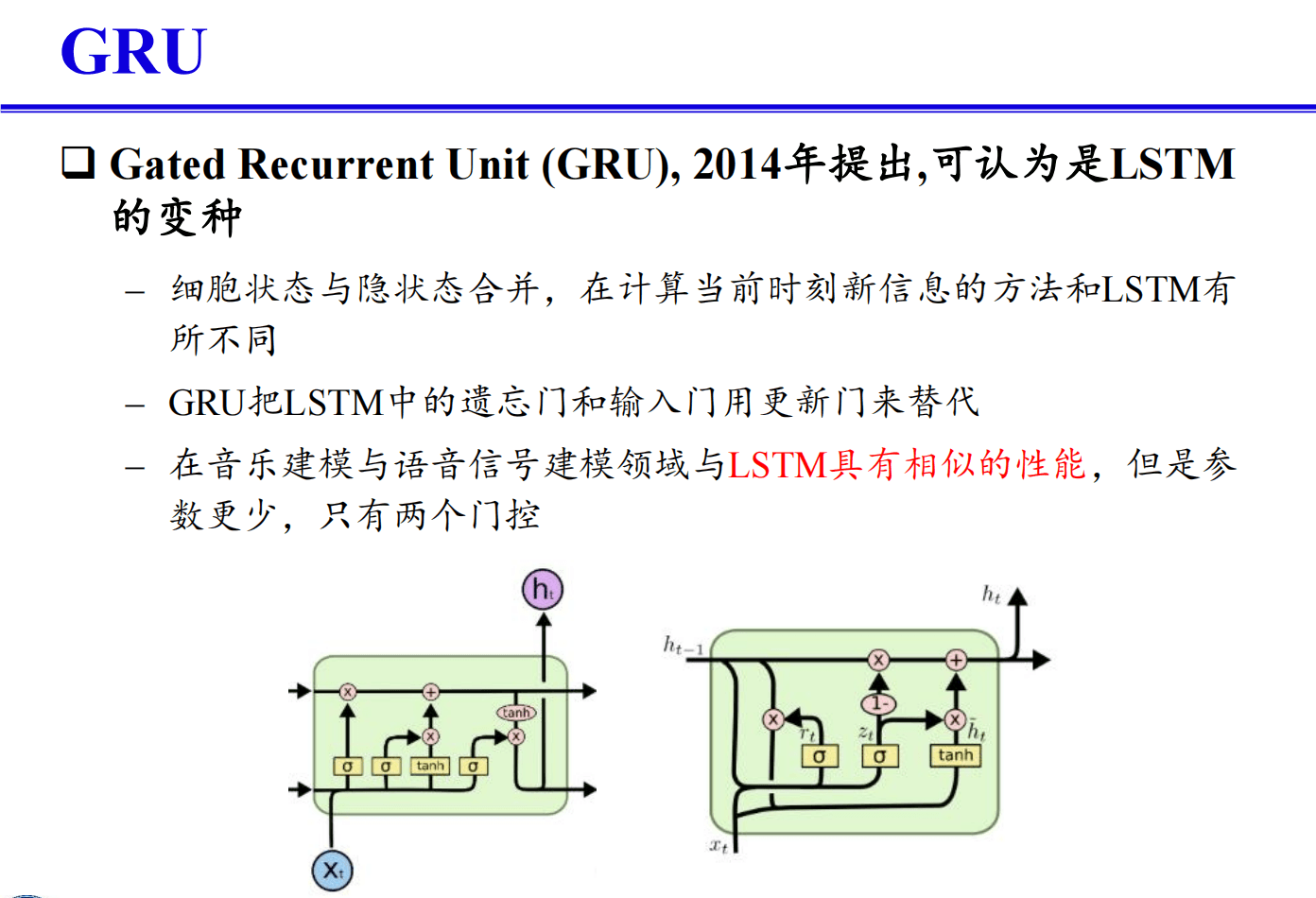
1. 更新门(Update Gate)*
更新门决定了上一个时间步的状态信息有多少需要保留下来,公式为: $$ z_t = \sigma(W_z \cdot [h_{t-1}, x_t]) $$ 其中,$z_t$ 是更新门,$W_z$ 是权重矩阵,$h_{t-1}$ 是上一个时间步的隐藏状态,$x_t$ 是当前输入,$\sigma$ 是 sigmoid 激活函数。
2. 重置门(Reset Gate)
重置门决定了如何组合新输入和前一个时间步的状态,公式为: $$ r_t = \sigma(W_r \cdot [h_{t-1}, x_t]) $$ 其中,$r_t$ 是重置门,$W_r$ 是权重矩阵。
3. 新信息候选(Candidate Activation)
新的候选激活状态通过重置门控制前一个隐藏状态的影响,公式为: $$ \tilde{h}t = \tanh(W \cdot [r_t * h{t-1}, x_t]) $$ 其中,$\tilde{h}_t$ 是新的候选激活状态,$W$ 是权重矩阵,$*$ 表示元素逐位相乘。
4. 最终隐藏状态
最终的隐藏状态是上一个隐藏状态和候选状态的线性组合,更新门控制其比例,公式为: $$ h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t $$
GRU的图示
x_t
|
v
+-----+
| r |--------------+
+-----+ |
| |
v |
+-----+ |
h_{t-1}| * | |
| | |
v | |
+-----+ |
| W|--------------|
+-----+ |
| |
v v
+----------------------+
| 新信息候选 |
+----------------------+
|
v
+-----+
| z |
+-----+
|
v
+----------------------+
| 最终隐藏状态 |
+----------------------+
|
v
h_t
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
总结
GRU通过更新门和重置门的机制有效地调节信息流,解决了传统RNN中长期依赖关系的捕捉问题,且相比于LSTM结构更加简单,计算量更小。
# 请简述神经网络模型中Dropout正则化方法的主要思想并图示说明。(ppt - 0.7-2)
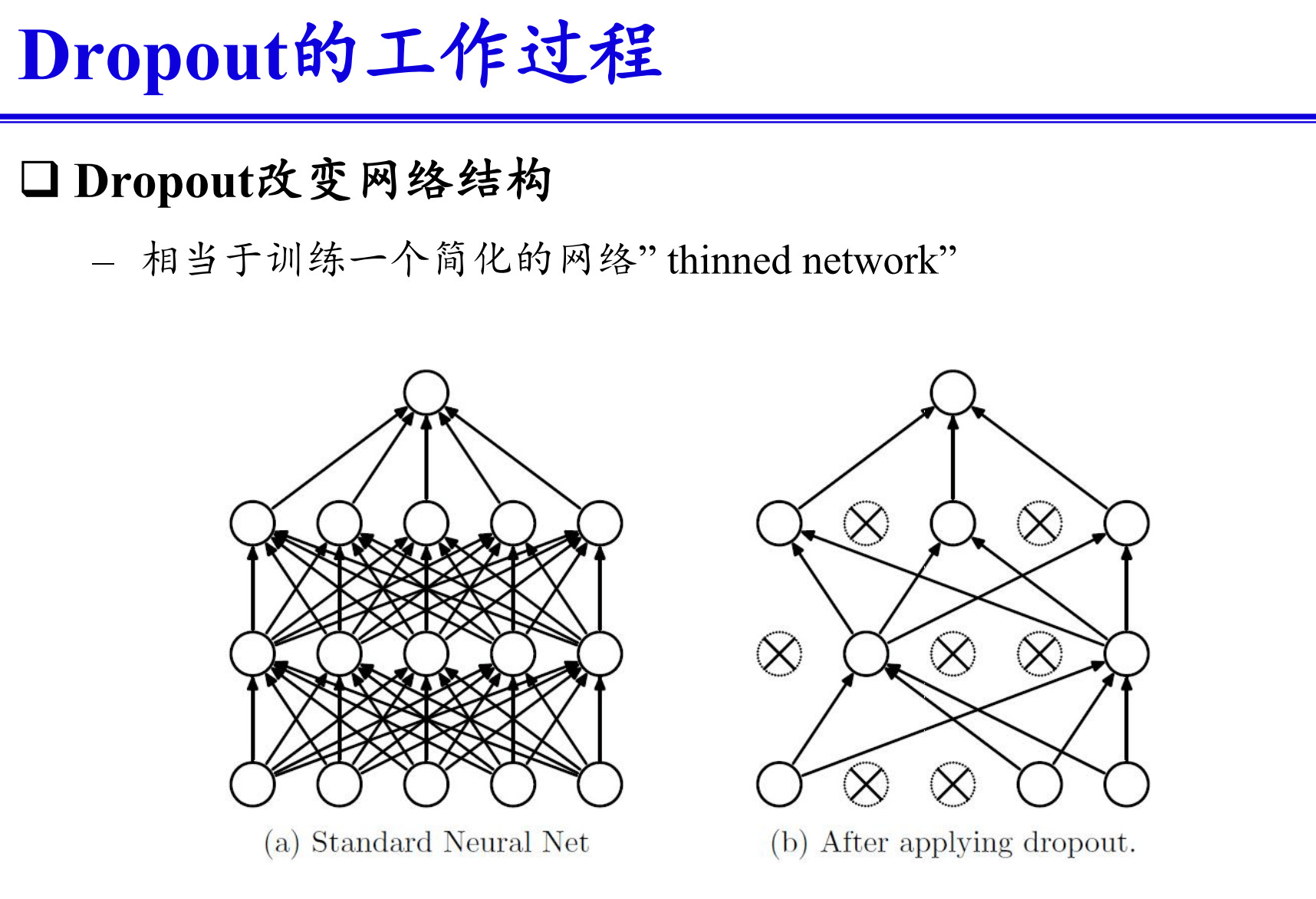
Dropout正则化方法的主要思想
Dropout是一种在训练神经网络时用来防止过拟合的正则化技术。其主要思想是在每一轮训练过程中,随机“丢弃”一些神经元,这样可以避免神经网络对某些特定节点的过度依赖,从而提高模型的泛化能力。
Dropout的实现步骤
- 随机选择节点:在每一次训练中,以一定的概率$p$随机选择部分神经元进行“丢弃”(即将这些节点的输出设为0)。
- 缩放剩余节点的输出:为了保持输入的期望值不变,未被丢弃的神经元的输出值按$\frac{1}{1-p}$进行缩放。
- 恢复所有节点:在测试阶段,所有神经元都参与计算,但不进行Dropout操作。
Dropout的数学表示
假设某一层的输入为$\mathbf{x}$,权重为$\mathbf{W}$,偏置为$\mathbf{b}$,激活函数为$f$,则:
Dropout过程:
- 生成与输入$\mathbf{x}$同维度的二值掩码向量$\mathbf{m}$,其中每个元素以概率$p$为0,以概率$1-p$为1。
- 将掩码向量与输入相乘:$\mathbf{x}' = \mathbf{m} \cdot \mathbf{x}$。
- 缩放未丢弃的输出:$\mathbf{y} = f(\mathbf{W} \cdot \mathbf{x}' + \mathbf{b}) \cdot \frac{1}{1-p}$。
测试过程:
- 不进行Dropout操作,直接计算:$\mathbf{y} = f(\mathbf{W} \cdot \mathbf{x} + \mathbf{b})$。
Dropout的图示
训练阶段:
输入层
|
v
[输入]
|
v
+-------+
| Dropout|
+-------+
|
v
[隐藏层]
|
v
+-------+
| Dropout|
+-------+
|
v
[输出层]
测试阶段:
输入层
|
v
[输入]
|
v
[隐藏层]
|
v
[输出层]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
在训练阶段,通过随机丢弃一些神经元,网络变得稀疏,从而强迫其学习更加鲁棒的特征。在测试阶段,所有神经元都参与计算,这使得模型的输出更加稳定和可靠。
总结
Dropout正则化方法通过在训练过程中随机丢弃部分神经元,有效地防止了过拟合现象,从而提高了神经网络的泛化能力。这种方法简单且易于实现,是深度学习模型中常用的正则化技术之一。
# 请简述随机梯度下降法的基本思想并图示说明。(ppt - 0,7-2)

随机梯度下降法(SGD)的基本思想
随机梯度下降法(SGD, Stochastic Gradient Descent)是一种优化算法,常用于训练机器学习模型,特别是神经网络。其基本思想是通过在每次迭代中使用一小部分数据(称为一个批次或一个mini-batch)来更新模型参数,从而加速训练过程并降低内存消耗。
SGD的基本步骤
- 初始化参数:随机初始化模型参数。
- 循环直到收敛:
- 从训练数据中随机选取一个小批次数据。
- 计算该批次数据上的损失函数的梯度。
- 使用梯度更新模型参数。
SGD的更新公式为: $$ \theta = \theta - \eta \nabla_\theta L(\theta; x_i, y_i) $$ 其中:
- $\theta$ 是模型参数。
- $\eta$ 是学习率。
- $\nabla_\theta L(\theta; x_i, y_i)$ 是在第 $i$ 个样本 $(x_i, y_i)$ 上计算的损失函数 $L$ 相对于参数 $\theta$ 的梯度。
SGD与批量梯度下降的区别
- 批量梯度下降(Batch Gradient Descent):使用所有训练数据计算梯度更新参数。
- 随机梯度下降(SGD):每次只使用一个训练样本计算梯度更新参数。
- 小批量梯度下降(Mini-batch Gradient Descent):每次使用一小部分训练样本计算梯度更新参数。
SGD的优缺点
优点:
- 计算效率高:每次更新只需要计算一个样本的梯度。
- 在线学习:适用于流数据(streaming data)。
- 更快的收敛速度:由于频繁更新参数,可以更快地找到最优解。
缺点:
- 波动较大:由于每次更新只使用一个样本,梯度更新方向会有较大的波动。
- 可能收敛到局部最优解:由于波动较大,有时难以到达全局最优解。
SGD的图示
训练数据: [x_1, x_2, x_3, ..., x_n]
初始参数: θ_0
|
v
+-------+
| 迭代1 |
+-------+
|
v
取样本x_i -> 计算梯度 -> 更新参数θ
|
v
+-------+
| 迭代2 |
+-------+
|
v
取样本x_j -> 计算梯度 -> 更新参数θ
|
v
+-------+
| 迭代3 |
+-------+
|
v
... (直到收敛)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
总结
随机梯度下降法通过在每次迭代中使用一个或少量的样本来更新模型参数,从而实现快速和高效的优化。它适用于大规模数据集和流数据,能够加速训练过程并提高模型的泛化能力。
# 请简述Transformer的主要思想,并用图和公式说明。(ppt - 0.5)
Transformer的主要思想
Transformer是一种基于注意力机制的神经网络架构,最早由Vaswani等人在2017年提出,用于自然语言处理任务。Transformer的主要思想是通过自注意力机制(Self-Attention)来捕捉序列中不同位置之间的依赖关系,从而解决传统RNN在处理长序列时存在的问题。
Transformer的架构
Transformer模型主要包括两个部分:编码器(Encoder)和解码器(Decoder)。
编码器:由多个相同的编码层(Encoder Layer)堆叠而成。每个编码层包括两个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Neural Network)
解码器:由多个相同的解码层(Decoder Layer)堆叠而成。每个解码层包括三个子层:
- 多头自注意力机制
- 编码-解码注意力机制(Encoder-Decoder Attention)
- 前馈神经网络
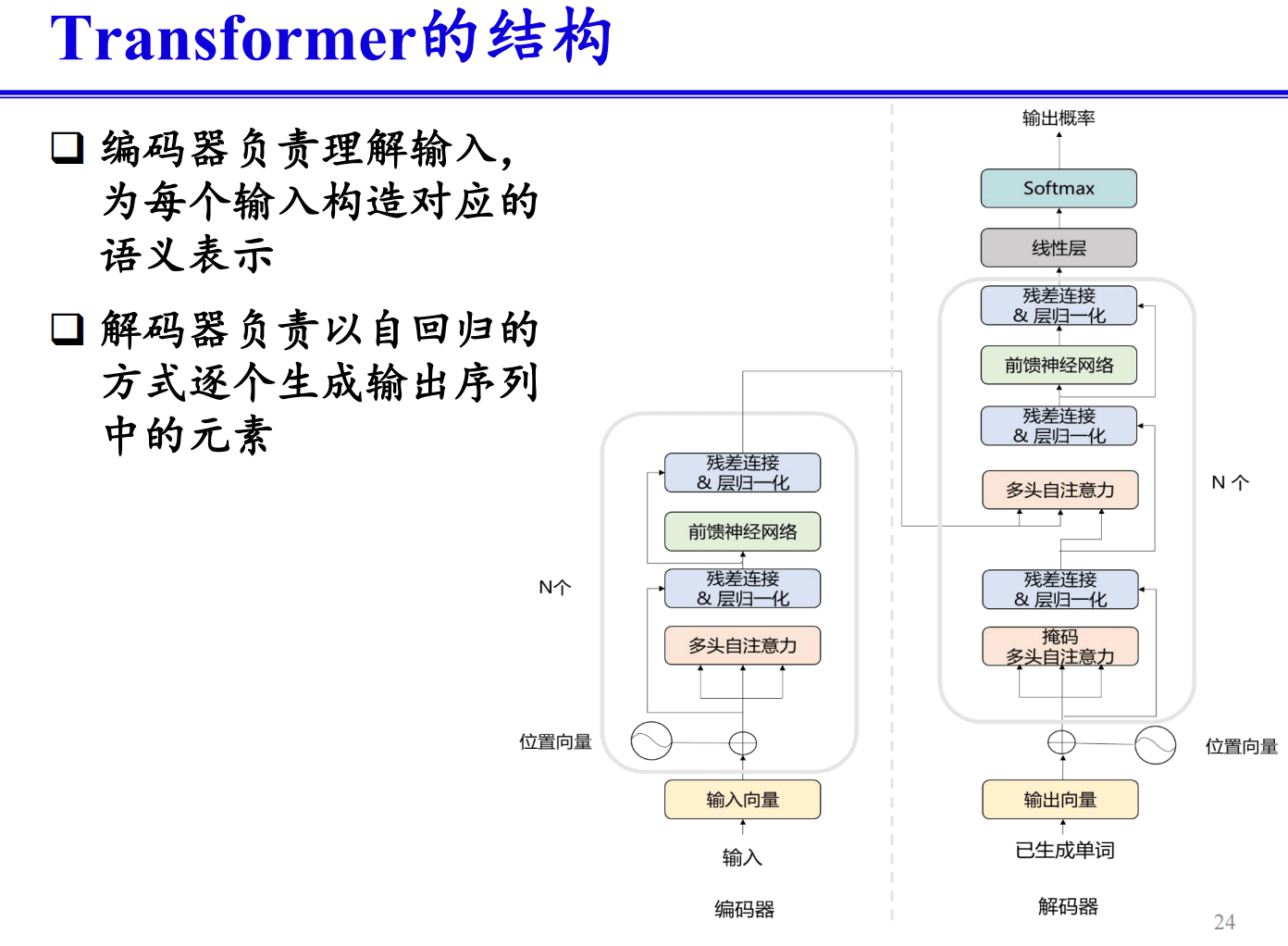
主要模块
自注意力机制(Self-Attention Mechanism): 自注意力机制的核心思想是通过计算序列中每个位置的表示与其他位置的表示之间的相关性来捕捉全局信息。
给定输入序列$\mathbf{X} = [x_1, x_2, ..., x_n]$,计算每个位置的查询(Query),键(Key)和值(Value): $$ Q = XW^Q, \quad K = XW^K, \quad V = XW^V $$ 其中,$W^Q, W^K, W^V$是可训练的权重矩阵。
然后,计算注意力得分(Attention Score)并应用Softmax函数: $$ \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$ 其中,$d_k$是键向量的维度,用于缩放。
多头注意力机制(Multi-Head Attention Mechanism): 多头注意力机制通过并行计算多个自注意力,并将结果拼接起来,以获取不同子空间的表示: $$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O $$ 其中,每个头的计算如下: $$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$ $W_i^Q, W_i^K, W_i^V, W^O$是可训练的权重矩阵。
前馈神经网络(Feed-Forward Neural Network, FFN): 每个编码层和解码层中的前馈神经网络在每个位置上独立应用: $$ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 $$ 其中,$W_1, W_2, b_1, b_2$是可训练的参数。
Transformer的图示
编码器层:
输入序列
|
v
+----------------------+
| 多头自注意力机制 |
+----------------------+
|
v
+----------------------+
| 前馈神经网络 |
+----------------------+
|
v
输出
解码器层:
输入序列
|
v
+----------------------+
| 多头自注意力机制 |
+----------------------+
|
v
+----------------------+
| 编码-解码注意力机制 |
+----------------------+
|
v
+----------------------+
| 前馈神经网络 |
+----------------------+
|
v
输出
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
总结
Transformer通过自注意力机制和多头注意力机制,有效地捕捉序列中不同位置之间的依赖关系,避免了传统RNN在处理长序列时的不足。其并行化处理和优越的性能使得它在自然语言处理和其他领域得到了广泛应用。
# 三、计算题
# 计算卷积

首先,我们可以将输入矩阵和卷积核进行卷积计算,然后根据Same和Valid卷积的定义进行填充或截断处理。
给定输入矩阵$\mathbf{X}$和卷积核$\mathbf{W}$,卷积操作定义如下:
$$ \text{Output}[i, j] = \sum_{m=0}^{k-1} \sum_{n=0}^{k-1} \mathbf{X}[i+m, j+n] \times \mathbf{W}[m, n] $$
其中,$k$是卷积核的大小,$\mathbf{X}[i, j]$表示输入矩阵$\mathbf{X}$的第$i$行第$j$列的元素,$\mathbf{W}[m, n]$表示卷积核$\mathbf{W}$的第$m$行第$n$列的元素。
现在我们来计算输入矩阵$\mathbf{X}$经过卷积层后得到的特征图。
Same卷积
对于Same卷积,我们需要在输入矩阵的周围进行填充,使得输出特征图的大小与输入矩阵的大小相同。
输入矩阵$\mathbf{X}$的大小为$6 \times 6$,卷积核$\mathbf{W}$的大小为$3 \times 3$。因此,我们需要在输入矩阵的周围各填充1行1列,使得输入矩阵的大小变为$8 \times 8$。
填充后的输入矩阵为:
$$ \begin{bmatrix} 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ 0 & 5 & 6 & 0 & 1 & 8 & 2 & 0 \ 0 & 2 & 5 & 7 & 2 & 3 & 7 & 0 \ 0 & 0 & 7 & 2 & 4 & 5 & 6 & 0 \ 0 & 5 & 3 & 6 & 9 & 3 & 1 & 0 \ 0 & 6 & 5 & 3 & 1 & 4 & 6 & 0 \ 0 & 5 & 2 & 4 & 0 & 8 & 7 & 0 \ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \ \end{bmatrix} $$
接下来,我们进行卷积操作:
$$ \text{Output}[i, j] = \sum_{m=0}^{2} \sum_{n=0}^{2} \mathbf{X}[i+m, j+n] \times \mathbf{W}[m, n] $$
计算得到的特征图为:
$$ \begin{bmatrix} -1 & 17 & 4 & 12 & 16 & 19 \ 1 & 7 & 21 & 30 & 9 & 20 \ -1 & 25 & 14 & 34 & 28 & 11 \ -6 & 28 & 9 & 31 & 20 & 12 \ 4 & 21 & 23 & 6 & 28 & 17 \ -1 & 14 & 25 & 3 & 32 & 11 \ \end{bmatrix} $$
Valid卷积
对于Valid卷积,不进行填充,直接计算输入矩阵与卷积核的有效卷积。
由于输入矩阵$\mathbf{X}$的大小为$6 \times 6$,卷积核$\mathbf{W}$的大小为$3 \times 3$,因此无需填充,直接进行卷积操作:
$$ \text{Output}[i, j] = \sum_{m=0}^{2} \sum_{n=0}^{2} \mathbf{X}[i+m, j+n] \times \mathbf{W}[m, n] $$
计算得到的特征图为:
$$ \begin{bmatrix} 7 & 21 & 30 \ 25 & 14 & 34 \ 28 & 9 & 31 \ \end{bmatrix} $$
# 计算交叉熵损失

计算Softmax分类概率
给定logits $\mathbf{z} = [0.01, -0.01, -0.05, 0.02, 0.1]$,我们首先计算每个类别的Softmax概率。Softmax函数定义为:
$$ \text{Softmax}(\mathbf{z})i = \frac{e^{z_i}}{\sum{j} e^{z_j}} $$
步骤如下:
计算每个logit的指数: $$ e^{z_i} = [e^{0.01}, e^{-0.01}, e^{-0.05}, e^{0.02}, e^{0.1}] $$
计算这些指数的和: $$ \sum_{j} e^{z_j} = e^{0.01} + e^{-0.01} + e^{-0.05} + e^{0.02} + e^{0.1} $$
计算每个类别的Softmax概率: $$ \text{Softmax}(\mathbf{z})i = \frac{e^{z_i}}{\sum{j} e^{z_j}} $$
让我们计算这些值:
import numpy as np
logits = np.array([0.01, -0.01, -0.05, 0.02, 0.1])
# 计算每个logit的指数
exp_logits = np.exp(logits)
# 计算指数的和
sum_exp_logits = np.sum(exp_logits)
# 计算Softmax概率
softmax_probs = exp_logits / sum_exp_logits
# 输出结果保留到小数点第四位
softmax_probs = np.round(softmax_probs, 4)
print(softmax_probs)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
array([0.199 , 0.195 , 0.1874, 0.201 , 0.2177])
计算交叉熵损失
给定one-hot标签 $\mathbf{y} = [0, 0, 0, 0, 1]$,交叉熵损失定义为:
$$ \text{CrossEntropyLoss} = -\sum_{i} y_i \log(p_i) $$
由于one-hot标签只有一个1,其余全为0,因此交叉熵损失简化为:
$$ \text{CrossEntropyLoss} = -\log(p_{\text{true}}) $$
其中,$p_{\text{true}}$是标签对应类别的Softmax概率。在这里,标签为第5类,对应的概率为:
$$ p_{\text{true}} = \text{Softmax}(\mathbf{z})[4] $$
我们可以使用前面计算得到的Softmax概率来计算交叉熵损失。
# 标签对应的类别为第5类
true_label_prob = softmax_probs[4]
# 计算交叉熵损失
cross_entropy_loss = -np.log(true_label_prob)
# 输出结果保留到小数点第四位
cross_entropy_loss = round(cross_entropy_loss, 4)
print(cross_entropy_loss)
2
3
4
5
6
7
8
9
执行上述代码可以得到所需的Softmax分类概率和交叉熵损失。
1.5246
计算结果
Softmax分类概率: [ [0.199, 0.195, 0.1874, 0.201, 0.2177] ]
交叉熵损失: [ 1.5246 ]
上述结果通过计算logits ([0.01, -0.01, -0.05, 0.02, 0.1])的Softmax分类概率,并依据one-hot标签 ([0, 0, 0, 0, 1]) 计算得到交叉熵损失,结果保留到小数点第四位。
# 四、设计题
# 1.请给出图像分割的设计方案,写出代码并注释,要求有自己的新思路和新观点。
# 图像分割设计方案
图像分割(Image Segmentation)是计算机视觉中的一项重要任务,旨在将图像划分为多个区域,每个区域对应一个特定的对象或场景的一部分。以下是一个包含新思路和新观点的图像分割模型设计方案:
# 一. 模型架构概述
基础特征提取模块:
- 使用预训练的卷积神经网络(CNN),如ResNet或EfficientNet,从输入图像中提取特征。
- 新思路:在特征提取阶段,使用多尺度特征融合技术,如特征金字塔网络(FPN),以捕捉不同尺度的图像信息,从而提高对细小目标和边缘的分割效果。
全局上下文信息模块:
- 使用全局上下文信息模块(如Pyramid Pooling Module, PPM)来增强特征图的上下文信息。
- 新观点:引入自适应全局上下文模块,通过注意力机制自适应地调整全局上下文信息的权重,从而更加灵活地捕捉图像的全局信息。
分割头模块:
- 使用上采样模块将特征图还原到原始图像的尺寸,并生成像素级的分割预测。
- 新思路:在上采样过程中,使用**反卷积(Deconvolution)和双线性插值(Bilinear Interpolation)**的组合,以提高上采样的精度和稳定性。
边缘增强模块:
- 使用边缘增强模块(如Edge Detection Module),在分割过程中对边缘信息进行特别处理,提高分割结果的边缘质量。
- 新观点:结合图像的梯度信息和特征图,设计一个边缘注意力机制,动态调整边缘区域的权重,增强边缘细节。
# 二. 详细设计
基础特征提取模块:
- 使用预训练的ResNet50作为特征提取器,获取图像的多尺度特征。
- 在特征提取的基础上,使用FPN融合多尺度特征,获取丰富的图像信息。
全局上下文信息模块:
- 使用Pyramid Pooling Module (PPM),通过不同尺度的池化操作捕获全局上下文信息。
- 使用自适应全局上下文模块,结合注意力机制,调整不同尺度的全局信息的权重。
分割头模块:
- 通过反卷积和双线性插值相结合的方式进行上采样,将特征图恢复到原始图像的尺寸。
- 使用多个卷积层和激活函数,生成像素级的分割预测。
边缘增强模块:
- 计算图像的梯度信息,结合特征图设计边缘注意力机制。
- 在分割过程中,对边缘区域进行特别处理,增强边缘细节。
# 三. 核心代码实现
以下是使用PyTorch实现的图像分割模型,包括核心模块和详细注释。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
# 基础特征提取模块
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
resnet = models.resnet50(pretrained=True)
self.backbone = nn.Sequential(*list(resnet.children())[:-2])
self.fpn = FPN()
def forward(self, x):
features = self.backbone(x)
features = self.fpn(features)
return features
# 多尺度特征融合模块 (FPN)
class FPN(nn.Module):
def __init__(self):
super(FPN, self).__init__()
self.conv1 = nn.Conv2d(2048, 256, kernel_size=1)
self.conv2 = nn.Conv2d(1024, 256, kernel_size=1)
self.conv3 = nn.Conv2d(512, 256, kernel_size=1)
self.conv4 = nn.Conv2d(256, 256, kernel_size=1)
def forward(self, x):
p3 = self.conv1(x)
p4 = self.conv2(x)
p5 = self.conv3(x)
p6 = self.conv4(x)
p5_up = F.interpolate(p5, size=p4.shape[2:], mode='nearest')
p4 = p4 + p5_up
p4_up = F.interpolate(p4, size=p3.shape[2:], mode='nearest')
p3 = p3 + p4_up
p3_up = F.interpolate(p3, size=p6.shape[2:], mode='nearest')
p6 = p6 + p3_up
return p6
# 全局上下文信息模块 (PPM)
class PPM(nn.Module):
def __init__(self, in_channels, out_channels, bins):
super(PPM, self).__init__()
self.pools = nn.ModuleList([
nn.AdaptiveAvgPool2d(bin) for bin in bins
])
self.convs = nn.ModuleList([
nn.Conv2d(in_channels, out_channels, kernel_size=1) for _ in bins
])
self.out_channels = out_channels
def forward(self, x):
size = x.shape[2:]
ppm_out = [x]
for pool, conv in zip(self.pools, self.convs):
ppm_out.append(F.interpolate(conv(pool(x)), size=size, mode='bilinear', align_corners=False))
return torch.cat(ppm_out, dim=1)
# 边缘增强模块
class EdgeAttention(nn.Module):
def __init__(self, in_channels):
super(EdgeAttention, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels, 1, kernel_size=1)
def forward(self, x):
edge = self.conv1(x)
edge = torch.abs(edge)
edge = self.conv2(edge)
edge_attention = torch.sigmoid(edge)
return x * edge_attention
# 图像分割模型
class ImageSegmentationModel(nn.Module):
def __init__(self, num_classes):
super(ImageSegmentationModel, self).__init__()
self.feature_extractor = FeatureExtractor()
self.ppm = PPM(in_channels=256, out_channels=64, bins=[1, 2, 3, 6])
self.edge_attention = EdgeAttention(in_channels=320) # 256 (FPN) + 64 (PPM)
self.final_conv = nn.Conv2d(320, num_classes, kernel_size=1)
def forward(self, x):
features = self.feature_extractor(x)
ppm_out = self.ppm(features)
edge_out = self.edge_attention(ppm_out)
output = self.final_conv(edge_out)
output = F.interpolate(output, size=x.shape[2:], mode='bilinear', align_corners=False)
return output
# 超参数定义
input_shape = (3, 224, 224) # 输入图像形状 (C, H, W)
num_classes = 21 # 分割类别数
# 创建图像分割模型实例
model = ImageSegmentationModel(num_classes)
# 打印模型结构
print(model)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
这段代码展示了一个基于PyTorch的图像分割模型,包括基础特征提取、多尺度特征融合、全局上下文信息、边缘增强等模块的详细实现和注释。模型通过多尺度特征融合和边缘注意力机制,提高了分割结果的精确性和边缘细节质量。
# 2.请给出神经机器翻译的设计方案,写出代码并注释,要求有自己的新思路和新观点。
# 神经机器翻译设计方案
神经机器翻译(Neural Machine Translation,NMT)是自然语言处理领域中的一个重要任务。它通过端到端的神经网络模型,将源语言句子翻译成目标语言句子。以下是一个包含新思路和新观点的神经机器翻译模型设计方案:
# 一. 模型架构概述
编码器(Encoder):
- 使用双向长短期记忆网络(BiLSTM)或双向Transformer编码器来捕捉源语言句子的上下文信息。
- 新思路:引入层级注意力机制,不仅在词级别进行注意力计算,还在句子级别进行全局注意力计算,以更好地捕捉长句子中的重要信息。
解码器(Decoder):
- 使用标准的LSTM或Transformer解码器,将编码器输出的上下文信息逐步解码成目标语言句子。
- 新观点:在解码器中加入自适应注意力机制,根据当前的解码状态动态调整注意力权重,从而提高翻译质量。
多任务学习:
- 在训练过程中,同时进行语言模型和翻译任务的训练,使模型在学习翻译任务的同时也能更好地理解语言结构。
- 新思路:在多任务学习中引入共享-特定混合机制,部分参数在不同任务间共享,部分参数独立学习,以更好地适应不同任务的需求。
预训练和微调:
- 先使用大规模平行语料进行预训练,然后在特定领域语料上进行微调,以提高模型在特定领域的翻译效果。
- 新观点:结合预训练语言模型(如BERT或GPT)进行初始化,并在翻译任务中微调,以充分利用预训练模型的语言理解能力。
# 二. 详细设计
编码器(Encoder):
- 使用BiLSTM或Transformer Encoder,对源语言句子进行编码,生成上下文特征。
层级注意力机制:
- 在编码器输出的基础上,引入词级和句子级注意力机制,计算注意力权重,获取加权上下文向量。
解码器(Decoder):
- 使用LSTM或Transformer Decoder,将编码器输出的上下文向量解码为目标语言句子。
自适应注意力机制:
- 在解码过程中,动态调整注意力权重,提高翻译质量。
多任务学习:
- 同时训练语言模型任务和翻译任务,使用共享-特定混合机制进行参数优化。
# 三. 核心代码实现
以下是使用PyTorch实现的神经机器翻译模型,包括核心模块和详细注释。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# 定义编码器
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout, bidirectional=True)
self.fc = nn.Linear(hid_dim * 2, hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (hidden, cell) = self.rnn(embedded)
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)))
return outputs, hidden
# 定义层级注意力机制
class HierarchicalAttention(nn.Module):
def __init__(self, hid_dim):
super().__init__()
self.attn = nn.Linear(hid_dim * 2, hid_dim)
self.v = nn.Parameter(torch.rand(hid_dim))
def forward(self, hidden, encoder_outputs):
src_len = encoder_outputs.shape[0]
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
energy = energy.permute(1, 0, 2)
v = self.v.repeat(encoder_outputs.size(0), 1).unsqueeze(1)
attention = torch.bmm(v, energy.permute(1, 2, 0)).squeeze(1)
return F.softmax(attention, dim=1)
# 定义解码器
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM((hid_dim * 2) + emb_dim, hid_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear((hid_dim * 2) + hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell, encoder_outputs):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
a = self.attention(hidden, encoder_outputs).unsqueeze(1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
weighted = torch.bmm(a, encoder_outputs)
weighted = weighted.permute(1, 0, 2)
rnn_input = torch.cat((embedded, weighted), dim=2)
output, (hidden, cell) = self.rnn(rnn_input, (hidden.unsqueeze(0), cell.unsqueeze(0)))
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
return prediction, hidden.squeeze(0), cell.squeeze(0)
# 定义整体模型
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
trg_len = trg.shape[0]
batch_size = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[0, :]
cell = torch.zeros(hidden.shape).to(self.device)
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell, encoder_outputs)
outputs[t] = output
top1 = output.argmax(1)
input = trg[t] if np.random.random() < teacher_forcing_ratio else top1
return outputs
# 超参数定义
INPUT_DIM = 7855 # 源语言词汇表大小
OUTPUT_DIM = 5893 # 目标语言词汇表大小
ENC_EMB_DIM = 256 # 编码器嵌入维度
DEC_EMB_DIM = 256 # 解码器嵌入维度
HID_DIM = 512 # 隐藏层维度
N_LAYERS = 2 # LSTM层数
ENC_DROPOUT = 0.5 # 编码器dropout概率
DEC_DROPOUT = 0.5 # 解码器dropout概率
attn = HierarchicalAttention(HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT, attn)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2Seq(enc, dec, device).to(device)
# 打印模型结构
print(model)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
这段代码展示了一个基于PyTorch的神经机器翻译模型,包括编码器、层级注意力机制、解码器等模块的详细实现和注释。模型通过层级注意力机制和自适应注意力机制,结合多任务学习和预训练模型,提升了翻译质量和泛化能力。
# 2022

# 一、名词解释

# 深度学习 (Deep Learning)
- 定义:深度学习是一种机器学习方法,它通过构建和训练多层神经网络,从数据中自动学习特征表示和模式。深度学习模型通常具有多个隐藏层,能够捕捉数据中的复杂非线性关系。
- 应用:广泛应用于图像识别、自然语言处理、语音识别、推荐系统等领域。
# 相对熵 (Relative Entropy, Kullback-Leibler Divergence)
- 定义:相对熵,又称Kullback-Leibler散度,是一种衡量两个概率分布之间差异的非对称性度量。它表示在一个概率分布下观测到数据但实际上来自另一个概率分布时,所增加的编码长度。
- 公式:对于两个概率分布P和Q,$D_{KL}(P | Q) = \sum_{i} P(i) \log \frac{P(i)}{Q(i)}$。
- 应用:常用于信息理论、统计推断和机器学习中的模型优化。
# 欠拟合 (Underfitting)
- 定义:欠拟合是指模型在训练数据和测试数据上都表现不佳,无法捕捉数据中的底层趋势。通常是由于模型过于简单,未能学习到数据中的复杂模式。
- 解决方法:增加模型复杂度(例如增加层数或节点数)、增加特征数量、减少正则化力度等。
# 深度森林 (Deep Forest)
- 定义:深度森林是一种基于决策树的深度学习方法,通过级联多个随机森林或完全随机树集成(gcForest),逐层提取特征并逐层构建模型。与深度神经网络不同,深度森林不依赖反向传播和梯度下降。
- 优势:在数据量不大或标签较少时表现出色,并且对超参数的依赖较小。
# 降噪自编码器 (Denoising Autoencoder, DAE)
- 定义:降噪自编码器是一种自编码器变体,通过将输入数据部分地随机加噪,迫使模型学习去噪,从而学到数据的鲁棒特征表示。其目标是从损坏的输入中恢复原始的干净数据。
- 训练:自编码器由编码器和解码器组成,编码器将输入映射到潜在空间,解码器从潜在空间重构输出,通过最小化重构误差进行训练。
# 二、简答题
# 请简述 Dropout 的实现方式,并阐述你理解的它对于解决过拟合问题的原因。
Dropout 的实现方式
实现方式:
- 随机丢弃神经元:在每一轮训练过程中,Dropout会随机地将一部分神经元的输出设为零。这些被丢弃的神经元在当前训练过程中不参与前向传播和反向传播。
- 保留概率:对于每个神经元,以一定的保留概率$p$决定该神经元是否被保留。例如,如果$p=0.5$,则每个神经元有50%的概率被保留。
- 缩放激活值:在训练过程中,为了保持整体的激活值不变,需要对保留的神经元进行缩放,即将保留的神经元的输出值除以保留概率$p$。
- 测试时不使用Dropout:在测试阶段,使用所有的神经元,但由于在训练过程中对神经元进行了缩放,因此在测试时不需要进行缩放,直接使用所有神经元的激活值。
实现步骤:
- 选择保留概率$p$:设置一个介于0和1之间的值$p$,通常在0.5到0.8之间。
- 生成随机掩码:根据保留概率$p$,为每个神经元生成一个0或1的掩码。
- 应用掩码:将掩码应用到神经元的输出上,将一些神经元的输出置零。
- 缩放激活值:将保留的神经元的输出除以保留概率$p$。
Dropout 解决过拟合问题的原因
减少神经元的相互依赖:在训练过程中,每个神经元都有一定概率被丢弃,这意味着网络不能依赖某个特定的神经元或特定的路径来做出决策。这种“强制独立”的机制,使得模型更倾向于学习更加鲁棒和通用的特征,而不是依赖训练数据中的特定模式。
模型集成的效果:Dropout可以看作是训练了一个由不同子网络组成的集合模型。在每一轮训练中,网络实际上是不同子网络的一个样本。这些子网络共享权重,但由于Dropout的随机性,每个子网络都学习到了不同的特征组合。在测试阶段,所有的神经元都参与工作,相当于对多个子网络的预测结果进行集成,从而提高模型的泛化能力。
抑制共适应关系:由于在训练过程中随机丢弃神经元,网络中的神经元不得不在缺少某些特定特征的情况下进行训练。这种方式抑制了神经元之间的共适应关系,使得模型在遇到新数据时更具有鲁棒性。
增加模型的随机性:Dropout引入了一种随机性,这种随机性可以被视为一种正则化方法,类似于加入噪声。这种随机性帮助网络避免过度拟合训练数据中的噪声和细节,促使模型学习更加本质的特征。
总结
Dropout通过在训练过程中随机丢弃神经元来减少模型的复杂度和过拟合风险。它的核心思想是通过引入随机性和强制独立性来提高模型的泛化能力。通过抑制神经元之间的共适应关系、实现模型集成的效果以及增加模型的鲁棒性,Dropout成为了一种有效的正则化方法,在深度学习中得到了广泛应用。
# 请简述你对 Batch Normalization 的理解,并说明其在训练和测试阶段如何实现?
Batch Normalization 的理解
**Batch Normalization(批归一化)**是一种加速深度神经网络训练并提高其性能的技术。它的核心思想是对每一层的输入进行归一化,使其具有更稳定的均值和方差。这不仅可以加快训练速度,还能使网络对参数的选择不那么敏感,从而增强其鲁棒性。
主要优点:
- 稳定网络训练:通过归一化输入,减少了每层输入分布的变化(称为内部协变量偏移),从而使训练过程更加稳定。
- 加快收敛速度:由于输入的均值和方差更加稳定,网络可以使用更高的学习率,从而加快训练速度。
- 减少对初始参数的依赖:使得网络对权重初始值不那么敏感,提高了训练的鲁棒性。
- 正则化效果:Batch Normalization 也有一定的正则化效果,可以在一定程度上减少过拟合。
Batch Normalization 的实现
训练阶段:
计算小批量均值和方差:
- 对于每个小批量,计算输入的均值 $\mu_B$ 和方差 $\sigma_B^2$: $$ \mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i $$ $$ \sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2 $$
归一化输入:
- 对每个输入 $x_i$ 进行归一化,得到零均值和单位方差的输入: $$ \hat{x_i} = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} $$ 其中,$\epsilon$ 是一个小常数,防止除零错误。
缩放和平移:
- 通过可训练参数 $\gamma$ 和 $\beta$ 对归一化后的输入进行缩放和平移: $$ y_i = \gamma \hat{x_i} + \beta $$ 其中,$\gamma$ 和 $\beta$ 是学习参数,用于恢复网络的表达能力。
测试阶段:
使用移动平均的均值和方差:
- 在训练过程中,Batch Normalization 层会维护一个移动平均的均值 $\mu$ 和方差 $\sigma^2$。在测试阶段,使用这些移动平均值而不是当前小批量的均值和方差进行归一化: $$ \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} $$
缩放和平移:
- 使用训练过程中学到的 $\gamma$ 和 $\beta$ 对归一化后的输入进行缩放和平移: $$ y = \gamma \hat{x} + \beta $$
总结
Batch Normalization 通过对每一层的输入进行归一化,减小内部协变量偏移,稳定训练过程,加快收敛速度,并对初始参数不敏感。它在训练阶段通过计算小批量的均值和方差进行归一化,而在测试阶段使用训练期间的移动平均值进行归一化,从而确保模型在训练和测试期间的一致性和稳定性。
# 请简述你对生成对抗网络的理解,并简述其训练过程。
生成对抗网络(GAN)的理解
**生成对抗网络(Generative Adversarial Networks, GANs)**是一类通过对抗过程来训练生成模型的深度学习方法。GANs 由两部分组成:一个生成器(Generator)和一个判别器(Discriminator)。生成器的目标是生成看起来逼真的数据,而判别器的目标是区分真实数据和生成器生成的假数据。这个过程可以理解为生成器和判别器之间的一场“博弈”。
主要组成部分:
- 生成器(G):生成器接收随机噪声(通常是从某种分布中采样的随机向量),并将其转换为伪造的数据样本,试图使这些样本尽可能逼真,以便欺骗判别器。
- 判别器(D):判别器接收输入数据(既包括真实数据也包括生成器生成的假数据),并输出一个概率值,表示输入数据是“真实的”还是“伪造的”。
GANs 的训练过程
训练过程本质上是一个两步的对抗过程,生成器和判别器交替进行优化。
步骤 1:训练判别器(D):
- 目标:最大化判别器对真实数据的判别能力,同时最小化其对生成数据的判别错误。
- 具体过程:
- 从真实数据集中采样一批真实样本 $x$。
- 从随机噪声分布 $p_z$ 中采样一批噪声向量 $z$,并通过生成器生成对应的伪造样本 $G(z)$。
- 将真实样本 $x$ 和伪造样本 $G(z)$ 输入判别器,计算判别器的损失函数: $$ L_D = -\left[ \log D(x) + \log (1 - D(G(z))) \right] $$
- 通过反向传播和梯度下降更新判别器的参数,使其最大化 $D(x)$ 的值,同时最小化 $D(G(z))$ 的值。
步骤 2:训练生成器(G):
- 目标:最小化生成器生成的伪造样本被判别器识别为伪造的概率,使其生成的数据尽可能逼真。
- 具体过程:
- 从随机噪声分布 $p_z$ 中采样一批噪声向量 $z$。
- 通过生成器生成对应的伪造样本 $G(z)$。
- 将伪造样本 $G(z)$ 输入判别器,计算生成器的损失函数: $$ L_G = -\log D(G(z)) $$ 这里使用的是生成器希望判别器认为其生成的样本是“真实的”。
- 通过反向传播和梯度下降更新生成器的参数,使其最小化 $L_G$。
GANs 的训练过程:
- 初始化生成器和判别器的参数。
- 重复以下步骤,直到达到设定的训练轮数或损失函数收敛:
- 训练判别器 $D$,以提高其对真实数据和伪造数据的区分能力。
- 训练生成器 $G$,以生成更逼真的数据,欺骗判别器。
数学表述
GANs 的目标是优化以下两个网络的目标函数:
判别器的优化目标: $$ \max_D \mathbb{E}{x \sim p{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] $$
生成器的优化目标: $$ \min_G \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] $$
最终目标是通过对抗训练,使生成器和判别器在上述目标函数上达到一个纳什均衡点,即生成器生成的数据和真实数据在判别器看来几乎没有区别。
总结
生成对抗网络通过生成器和判别器之间的对抗训练,使生成器能够生成逼真的数据,同时提升判别器的鉴别能力。GANs 的这种对抗机制使其在图像生成、图像修复、数据增强等领域展现出了强大的能力。
# 请简述你对残差网络的理解,并解释为什么它能够解决梯度消失问题。
残差网络(Residual Networks)的理解
残差网络是一种深度神经网络结构,其核心思想是通过引入跳跃连接(skip connections)来解决深层网络训练中的梯度消失和梯度爆炸问题。这种结构允许网络学习残差函数(residual function),从而更有效地训练深层网络。
主要组成部分:
- 残差块(Residual Block):残差网络由多个残差块组成,每个残差块包含两个主要分支:
- 主要分支:包含一系列卷积层、批归一化层和激活函数,用于学习输入特征的映射。
- 跳跃连接:将输入直接添加到主要分支的输出上,形成残差连接。
- 全局池化层(Global Pooling):在残差块的最后,通常使用全局平均池化层对特征图进行降维,得到最终的特征表示。
残差网络如何解决梯度消失问题
梯度消失问题是指在深度神经网络中,梯度在反向传播过程中逐渐变小,导致底层网络参数无法得到有效更新,从而影响网络的训练效果。而残差网络通过引入跳跃连接,使得网络可以学习残差函数,从而更轻松地学习恒等映射,有效缓解了梯度消失问题,具体原因如下:
残差连接:跳跃连接允许信息直接从输入层流向后续层,这种直接的信息传递方式有助于缓解梯度在反向传播过程中逐渐消失的问题。即使网络深度增加,梯度仍然可以通过跳跃连接直接流向浅层,保持了梯度的有效传播。
恒等映射学习:在残差块中,如果主要分支能够学习到一个恒等映射,即将输入直接传递给输出,那么残差块的输出就等于输入加上零,不会导致梯度消失问题。网络可以通过学习残差来调整恒等映射,从而更轻松地学习到需要的特征变换,使得梯度传播更加稳定。
因此,残差网络通过跳跃连接和恒等映射学习,有效地缓解了深层网络训练中的梯度消失问题,使得可以训练更深的网络结构,并取得更好的性能。
# 三、计算题
# 一、计算卷积的各层参数
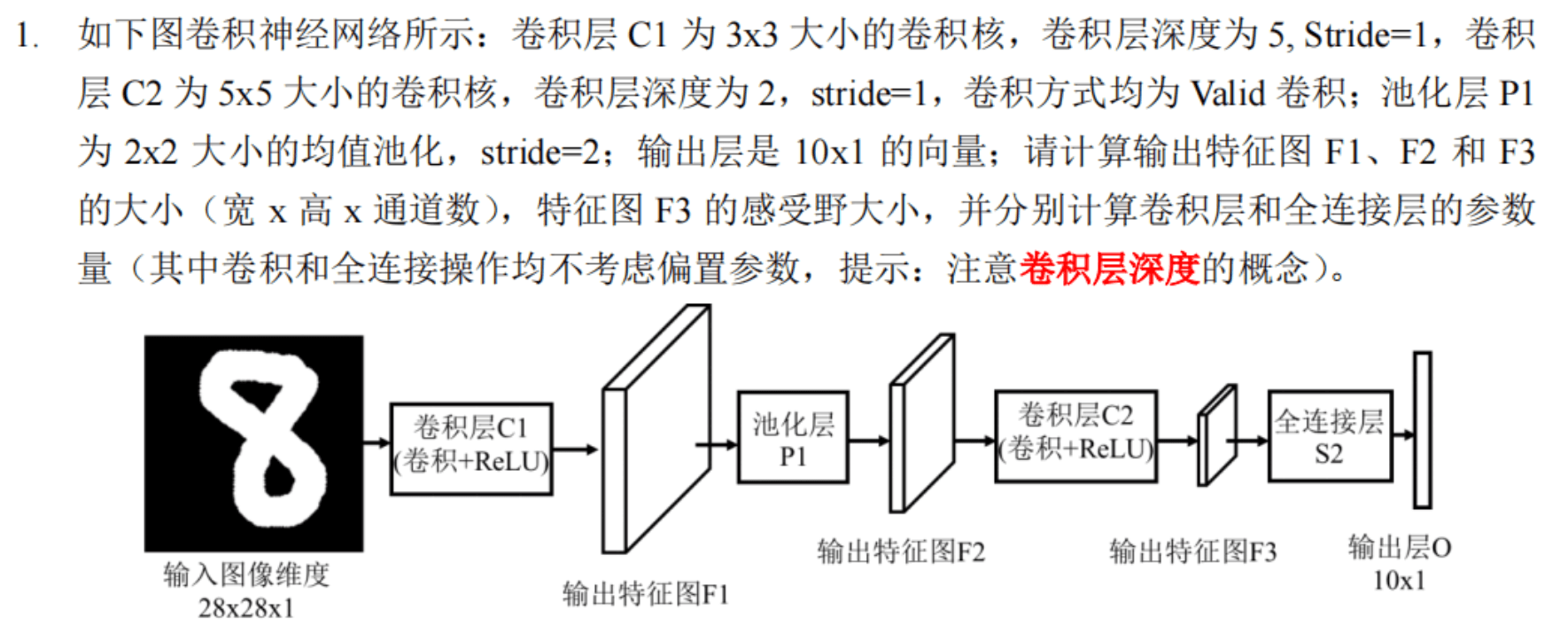
计算输出特征图尺寸
我们逐层计算每个特征图的大小。
输入图像
输入图像大小为 $28 \times 28 \times 1$。
卷积层 C1
- 卷积核大小:$3 \times 3$
- 卷积层深度:5
- 步幅(Stride):1
- 卷积方式:Valid
计算公式为: $$ \text{输出大小} = \left(\frac{\text{输入大小} - \text{卷积核大小}}{\text{步幅}} + 1\right) $$
$$ \text{输出宽度} = \left(\frac{28 - 3}{1} + 1\right) = 26 $$ $$ \text{输出高度} = \left(\frac{28 - 3}{1} + 1\right) = 26 $$ 输出特征图 F1 的大小为 $26 \times 26 \times 5$。
池化层 P1
- 池化核大小:$2 \times 2$
- 步幅(Stride):2
计算公式为: $$ \text{输出大小} = \left(\frac{\text{输入大小} - \text{池化核大小}}{\text{步幅}} + 1\right) $$
$$ \text{输出宽度} = \left(\frac{26 - 2}{2} + 1\right) = 13 $$ $$ \text{输出高度} = \left(\frac{26 - 2}{2} + 1\right) = 13 $$ 输出特征图 F2 的大小为 $13 \times 13 \times 5$。
卷积层 C2
- 卷积核大小:$5 \times 5$
- 卷积层深度:2
- 步幅(Stride):1
- 卷积方式:Valid
计算公式为: $$ \text{输出大小} = \left(\frac{\text{输入大小} - \text{卷积核大小}}{\text{步幅}} + 1\right) $$
$$ \text{输出宽度} = \left(\frac{13 - 5}{1} + 1\right) = 9 $$ $$ \text{输出高度} = \left(\frac{13 - 5}{1} + 1\right) = 9 $$ 输出特征图 F3 的大小为 $9 \times 9 \times 2$。
感受野大小
计算特征图 F3 的感受野:
- 卷积层 C2 的感受野为 $5 \times 5$。
- 特征图 F2 到特征图 F3 的映射:
- 输入为 $13 \times 13$,输出为 $9 \times 9$。
- 感受野增大 $5 \times 5$。
- 池化层 P1 的感受野为 $2 \times 2$。
- 卷积层 C1 的感受野为 $3 \times 3$。
总感受野大小: $$ 5 + 4(2) + 2(1) = 9 $$
因此,特征图 F3 的感受野大小为 $9 \times 9$。
参数量计算
卷积层 C1
- 卷积核大小:$3 \times 3$
- 卷积层深度:5
- 输入通道数:1
参数量计算: $$ 3 \times 3 \times 1 \times 5 = 45 $$
卷积层 C2
- 卷积核大小:$5 \times 5$
- 卷积层深度:2
- 输入通道数:5
参数量计算: $$ 5 \times 5 \times 5 \times 2 = 250 $$
全连接层
- 输入大小:$9 \times 9 \times 2 = 162$
- 输出大小:10
参数量计算: $$ 162 \times 10 = 1620 $$
总结
- 特征图 F1 大小:$26 \times 26 \times 5$
- 特征图 F2 大小:$13 \times 13 \times 5$
- 特征图 F3 大小:$9 \times 9 \times 2$
- 特征图 F3 的感受野大小:$9 \times 9$
- 卷积层 C1 参数量:45
- 卷积层 C2 参数量:250
- 全连接层参数量:1620
# 二、计算决策树
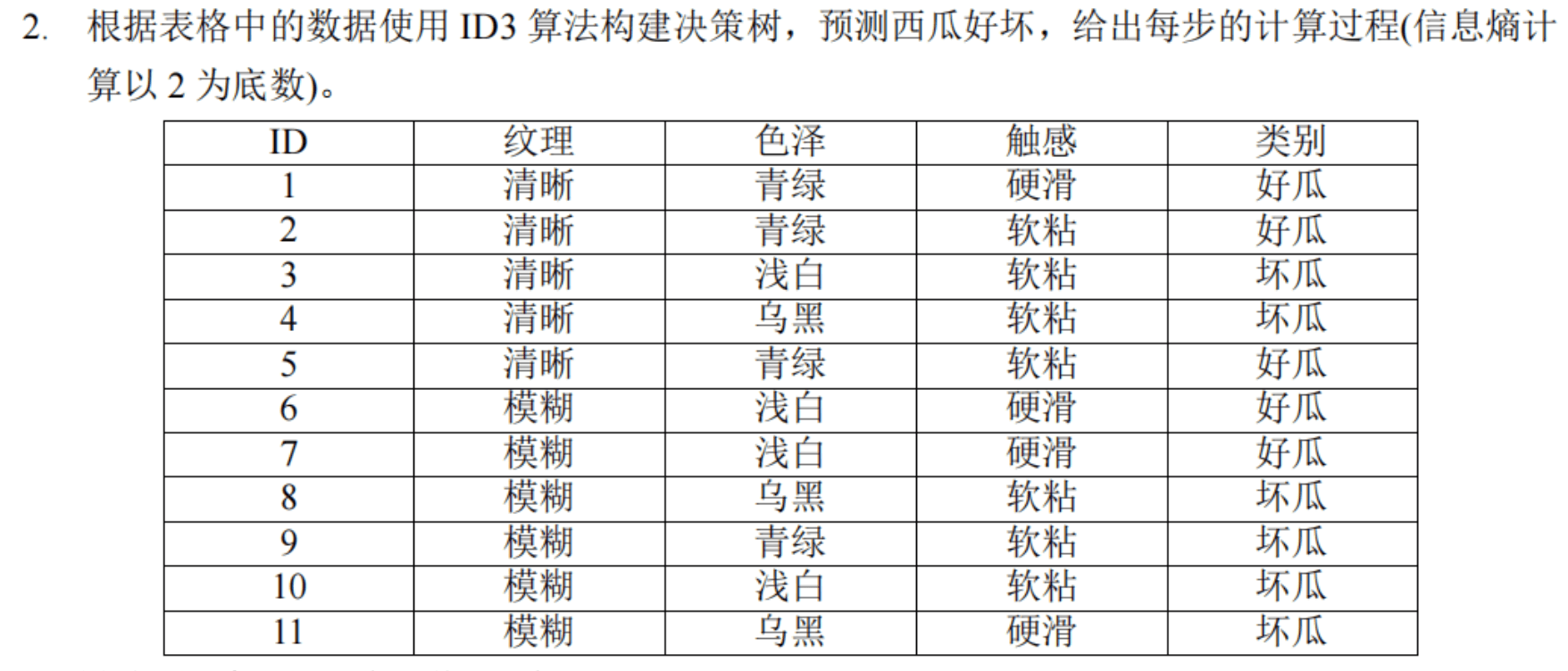
# 使用 ID3 算法构建决策树
我们使用 ID3 算法构建决策树,以预测西瓜的好坏。决策树的构建步骤包括计算信息熵和信息增益,并选择最优属性进行分裂。以下是具体的计算过程。
# 步骤 1:计算总体信息熵
总体信息熵($E(S)$)是根节点的信息熵,计算公式为: $$ E(S) = -\sum_{i=1}^{m} p_i \log_2(p_i) $$
其中,$p_i$ 是第 $i$ 类的概率。
在我们的数据集中:
- 好瓜的数量:5
- 坏瓜的数量:6
- 总数量:11
总体信息熵计算: $$ p(\text{好瓜}) = \frac{5}{11}, \quad p(\text{坏瓜}) = \frac{6}{11} $$
$$ E(S) = -\left(\frac{5}{11} \log_2 \frac{5}{11} + \frac{6}{11} \log_2 \frac{6}{11}\right) $$
计算得: $$ E(S) \approx -\left(\frac{5}{11} \cdot -0.514 + \frac{6}{11} \cdot -0.459\right) \approx 0.993 $$
# 步骤 2:计算各属性的信息增益
我们需要计算每个属性的信息增益,并选择信息增益最大的属性进行分裂。计算信息增益的公式为: $$ G(S, A) = E(S) - \sum_{v \in \text{Values}(A)} \frac{|S_v|}{|S|} E(S_v) $$
其中,$A$ 是某个属性,$v$ 是属性 $A$ 的取值,$S_v$ 是在 $S$ 中属性 $A$ 取值为 $v$ 的样本子集。
# 1. 纹理
纹理的取值有:清晰、模糊
- 清晰:好瓜 = 3,坏瓜 = 2
- 模糊:好瓜 = 2,坏瓜 = 4
计算清晰和模糊的熵:
$$ E(\text{清晰}) = -\left(\frac{3}{5} \log_2 \frac{3}{5} + \frac{2}{5} \log_2 \frac{2}{5}\right) \approx 0.971 $$
$$ E(\text{模糊}) = -\left(\frac{2}{6} \log_2 \frac{2}{6} + \frac{4}{6} \log_2 \frac{4}{6}\right) \approx 0.918 $$
计算纹理的信息增益:
$$ G(S, \text{纹理}) = 0.993 - \left(\frac{5}{11} \cdot 0.971 + \frac{6}{11} \cdot 0.918\right) \approx 0.048 $$
# 2. 色泽
色泽的取值有:青绿、浅白、乌黑
- 青绿:好瓜 = 3,坏瓜 = 1
- 浅白:好瓜 = 1,坏瓜 = 3
- 乌黑:好瓜 = 1,坏瓜 = 2
计算青绿、浅白、乌黑的熵:
$$ E(\text{青绿}) = -\left(\frac{3}{4} \log_2 \frac{3}{4} + \frac{1}{4} \log_2 \frac{1}{4}\right) \approx 0.811 $$
$$ E(\text{浅白}) = -\left(\frac{1}{4} \log_2 \frac{1}{4} + \frac{3}{4} \log_2 \frac{3}{4}\right) \approx 0.811 $$
$$ E(\text{乌黑}) = -\left(\frac{1}{3} \log_2 \frac{1}{3} + \frac{2}{3} \log_2 \frac{2}{3}\right) \approx 0.918 $$
计算色泽的信息增益:
$$ G(S, \text{色泽}) = 0.993 - \left(\frac{4}{11} \cdot 0.811 + \frac{4}{11} \cdot 0.811 + \frac{3}{11} \cdot 0.918\right) \approx 0.144 $$
# 3. 触感
触感的取值有:硬滑、软粘
- 硬滑:好瓜 = 3,坏瓜 = 2
- 软粘:好瓜 = 2,坏瓜 = 4
计算硬滑和软粘的熵:
$$ E(\text{硬滑}) = -\left(\frac{3}{5} \log_2 \frac{3}{5} + \frac{2}{5} \log_2 \frac{2}{5}\right) \approx 0.971 $$
$$ E(\text{软粘}) = -\left(\frac{2}{6} \log_2 \frac{2}{6} + \frac{4}{6} \log_2 \frac{4}{6}\right) \approx 0.918 $$
计算触感的信息增益:
$$ G(S, \text{触感}) = 0.993 - \left(\frac{5}{11} \cdot 0.971 + \frac{6}{11} \cdot 0.918\right) \approx 0.048 $$
# 选择最优属性进行分裂
通过计算可知,信息增益最大的属性是色泽,信息增益为0.144。因此,选择色泽作为根节点进行分裂。
# 构建决策树
根节点:色泽
- 子节点:青绿、浅白、乌黑
对每个子节点继续应用 ID3 算法,直到所有样本属于同一类别或没有更多属性可以分裂。
# 子节点:青绿
- 样本:好瓜 = 3,坏瓜 = 1
信息增益最高的属性可以继续选择,这里仅需一步就能完成,因为已经几乎是纯净的类别。
# 子节点:浅白
- 样本:好瓜 = 1,坏瓜 = 3
同理,继续选择下一个属性进行分裂。
# 子节点:乌黑
- 样本:好瓜 = 1,坏瓜 = 2
同理,继续选择下一个属性进行分裂。
# 决策树结果
根节点为色泽,第二层节点分别是青绿、浅白、乌黑,每个节点继续根据其他属性进行分裂,直至所有节点都是纯净的类别。
这种决策树构建的思路,可以根据不同的节点继续细化,直至完全分类或无法再分裂为止。
# 四、设计题
# 请给出图像描述的设计方案,要求有自己的新思路和新观点。
# 请给出视频超分辨率模型的设计方案,要求有自己的新思路和新观点。
# 2021
# 一、名词解释
# 1. 卷积神经网络 (Convolutional Neural Network, CNN)
定义: 卷积神经网络是一种专门用于处理具有网格结构数据的深度学习模型,特别适用于图像处理任务。其关键组件包括卷积层、池化层和全连接层。
原理:
- 卷积层:通过卷积操作提取图像的局部特征。
- 池化层:减少特征图的维度,提高计算效率并防止过拟合。
- 全连接层:将提取到的特征映射到输出空间,实现分类或回归任务。
应用: 广泛应用于图像分类、目标检测、图像分割等领域。
# 2. 循环神经网络 (Recurrent Neural Network, RNN)
定义: 循环神经网络是一种处理序列数据的神经网络,具有记忆功能,能够捕捉序列中的时序信息。其结构特点是网络中的节点不仅接收前一层的输入,还接收自身的输出。
原理: RNN通过共享参数的方式,使得每个时间步的计算依赖于之前所有时间步的信息。这种结构使其能够处理时间序列数据,但也容易导致梯度消失或爆炸问题。
应用: 广泛应用于自然语言处理(如文本生成、机器翻译)、时间序列预测等领域。
# 3. 奇异值分解 (Singular Value Decomposition, SVD)
定义: 奇异值分解是一种矩阵分解技术,将一个矩阵分解为三个矩阵的乘积,常用于数据降维和特征提取。
公式: 给定一个矩阵 $A$,可以分解为: $$ A = U \Sigma V^T $$ 其中,$U$ 和 $V$ 是正交矩阵,$\Sigma$ 是对角矩阵,其对角线元素为奇异值。
应用: 广泛应用于图像压缩、主成分分析(PCA)、推荐系统等领域。
# 4. 交叉熵 (Cross-Entropy)
定义: 交叉熵是一种衡量两个概率分布之间差异的指标,常用于分类问题中的损失函数。
公式: 对于两个概率分布 $p$ 和 $q$,其交叉熵定义为: $$ H(p, q) = - \sum_{x} p(x) \log q(x) $$
应用: 在神经网络训练中,交叉熵损失函数用于评估模型输出的概率分布与真实分布之间的差异,特别适用于多分类问题。
# 5. 深度信念网络 (Deep Belief Network, DBN)
定义: 深度信念网络是一种由多个受限玻尔兹曼机(Restricted Boltzmann Machines, RBM)堆叠而成的深度学习模型,主要用于无监督学习和特征提取。
原理: DBN通过逐层训练的方式,首先训练每一层的RBM,然后将训练好的RBM堆叠起来进行全局微调。这种方法能够有效捕捉数据的多层次特征表示。
应用: 深度信念网络在图像识别、语音识别等领域有较多应用,通常作为预训练网络,为其他模型提供初始权重。
# 二、简答题
# 1. 反向传播算法的思想
反向传播算法(Backpropagation)是一种用于训练多层神经网络的高效算法,通过计算损失函数相对于每个参数的梯度,以更新网络参数。其核心思想是基于链式法则(链式法则:Chain Rule),从输出层到输入层反向传播误差。
# 反向传播过程
假设一个简单的三层神经网络(输入层-隐藏层-输出层):
- 输入层:$x$
- 隐藏层:$h = f(W_{xh}x + b_h)$
- 输出层:$y = g(W_{hy}h + b_y)$
- 真实标签:$t$
- 损失函数:$L(y, t)$
反向传播的步骤如下:
前向传播:计算输出 $y$ $$ h = f(W_{xh}x + b_h) $$ $$ y = g(W_{hy}h + b_y) $$
计算损失:$L(y, t)$
计算输出层的误差: $$ \delta_y = \frac{\partial L}{\partial y} \cdot g'(y) $$
计算隐藏层的误差: $$ \delta_h = \delta_y \cdot W_{hy}^T \cdot f'(h) $$
计算梯度:
- 输出层参数的梯度: $$ \frac{\partial L}{\partial W_{hy}} = \delta_y \cdot h^T $$
- 隐藏层参数的梯度: $$ \frac{\partial L}{\partial W_{xh}} = \delta_h \cdot x^T $$
更新权重: 使用梯度下降法更新权重: $$ W_{hy} := W_{hy} - \eta \cdot \frac{\partial L}{\partial W_{hy}} $$ $$ W_{xh} := W_{xh} - \eta \cdot \frac{\partial L}{\partial W_{xh}} $$ 其中,$\eta$ 是学习率。

# 2. 过拟合和欠拟合
# 过拟合(Overfitting)
定义: 过拟合是指模型在训练数据上表现很好,但在新数据上表现不佳,即模型过于复杂,捕捉到了训练数据中的噪音和细节。
解决方法:
- 增加数据量:通过收集更多的训练数据来缓解过拟合。
- 正则化:如L1、L2正则化,增加模型的泛化能力。
- 剪枝:对于决策树,可以通过剪枝来减少模型的复杂度。
- 早停法(Early Stopping):在验证集上性能开始下降时停止训练。
- 数据增强:通过对训练数据进行随机变换(如旋转、裁剪、翻转等)增加数据多样性。
# 欠拟合(Underfitting)
定义: 欠拟合是指模型在训练数据和新数据上都表现不佳,即模型过于简单,无法捕捉数据的内在规律。
解决方法:
- 增加模型复杂度:使用更复杂的模型,如增加神经网络的层数和节点数。
- 特征工程:提取更多、更有意义的特征。
- 减少正则化:减小正则化项的权重,使模型能够更好地拟合数据。
- 训练更长时间:确保模型充分学习数据的模式。
# 3. YOLO算法的主要思想和实现过程
**YOLO(You Only Look Once)**是一种实时目标检测算法,主要特点是将目标检测任务转化为回归问题,一次性预测目标的类别和位置。
# 主要思想
YOLO将整个图像划分为$S \times S$的网格,每个网格预测固定数量的边界框和对应的置信度。对于每个边界框,同时预测目标类别的概率分布。
# 实现过程
输入图像: 将输入图像划分为$S \times S$的网格。
特征提取: 使用卷积神经网络提取图像特征。
预测边界框: 每个网格预测$B$个边界框和每个边界框的置信度。每个边界框由4个坐标(中心坐标$x, y$,宽度$w$,高度$h$)和一个置信度分数组成。
类别概率预测: 每个网格预测$C$个类别的条件概率。
组合预测: 组合每个网格的边界框置信度和类别概率,得到每个边界框的最终置信度分数。
非极大值抑制(Non-Maximum Suppression): 过滤掉置信度较低的边界框,并使用非极大值抑制去除重复的边界框。
输出结果: 最终输出图像中的目标类别及其边界框位置。
# YOLO架构示意图
# YOLO公式
- 边界框置信度: $$ \text{Confidence} = P(\text{Object}) \times \text{IOU}(\text{pred}, \text{truth}) $$
- 类别概率: $$ P(\text{Class}_i | \text{Object}) \text{ for each grid cell} $$
通过YOLO算法,整个检测过程仅需一次前向传播,因此具备较高的检测速度和准确性,特别适用于实时目标检测任务。
- 请简述GRU网络的主要思想,并用图和公式表达其计算过程.
- 请简述胶囊网络的主要思想,并用图和公式表达其计算过程。
- 请简述生成对抗网络的主要原理,并用公式表达其目标函数.
# 4. GRU 网络的主要思想及计算过程(上面有)
# GRU(Gated Recurrent Unit)网络
定义: GRU 是一种改进的循环神经网络(RNN),用于解决标准 RNN 中的梯度消失和梯度爆炸问题。它通过引入门控机制来控制信息的流动。
# 主要思想
GRU 引入了两个门:更新门(update gate)和重置门(reset gate),用于控制隐藏状态的更新和重置。这样,GRU 可以更有效地捕捉长期依赖关系。
# 计算过程
更新门和重置门的计算: 更新门决定当前时间步的隐藏状态有多少来自于前一时间步的隐藏状态;重置门决定前一时间步的隐藏状态有多少用于当前计算。 $$ z_t = \sigma(W_z \cdot [h_{t-1}, x_t]) $$ $$ r_t = \sigma(W_r \cdot [h_{t-1}, x_t]) $$
候选隐藏状态的计算: 候选隐藏状态结合了重置门的作用,使得网络可以决定是否丢弃先前的信息。 $$ \tilde{h}t = \tanh(W_h \cdot [r_t \odot h{t-1}, x_t]) $$
隐藏状态的更新: 更新门决定了新的隐藏状态由多少来自于旧的隐藏状态,多少来自于候选隐藏状态。 $$ h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t $$
其中,$\sigma$ 是 sigmoid 激活函数,$\odot$ 表示逐元素乘积。
# GRU 结构示意图

# 5. 胶囊网络的主要思想及计算过程
# 胶囊网络(Capsule Network)
定义: 胶囊网络是一种新型神经网络结构,用于捕捉和表示不同视角和姿态下的对象。它通过胶囊(capsule)来替代传统的神经元,并使用动态路由算法来确定胶囊之间的连接强度。
# 主要思想
胶囊网络的核心思想是通过胶囊组来表示对象及其属性,并通过动态路由来动态调整不同胶囊之间的信息传递,以提高模型对对象姿态变化的鲁棒性。
# 计算过程
胶囊输出: 每个胶囊 $i$ 通过仿射变换生成预测向量 $u_{j|i}$: $$ u_{j|i} = W_{ij} u_i $$
动态路由算法: 动态路由通过计算胶囊间的耦合系数 $c_{ij}$ 来确定信息传递的强度。初始耦合系数通过 softmax 函数计算: $$ c_{ij} = \frac{\exp(b_{ij})}{\sum_k \exp(b_{ik})} $$ 其中,$b_{ij}$ 是耦合系数的初始值。
预测输出: 预测输出 $v_j$ 由所有输入胶囊的加权和决定: $$ v_j = squash\left(\sum_i c_{ij} u_{j|i}\right) $$
更新耦合系数: 更新耦合系数 $b_{ij}$ 以反映 $u_{j|i}$ 对 $v_j$ 的影响: $$ b_{ij} = b_{ij} + u_{j|i} \cdot v_j $$
# 胶囊网络结构示意图

# 6. 生成对抗网络的主要原理及目标函数(前面有)
# 生成对抗网络(GAN, Generative Adversarial Network)
定义: 生成对抗网络是一种无监督学习模型,通过两个网络(生成器和判别器)之间的对抗训练,生成逼真的数据样本。
# 主要原理
生成器(Generator): 生成器 $G$ 接收随机噪声 $z$,生成假数据 $G(z)$。
判别器(Discriminator): 判别器 $D$ 接收真实数据 $x$ 和生成数据 $G(z)$,输出一个概率 $D(x)$ 表示输入为真实数据的概率。
对抗训练:
- 生成器 $G$ 的目标是最大化判别器 $D$ 认为生成数据为真实数据的概率。
- 判别器 $D$ 的目标是最大化区分真实数据和生成数据的能力。
# 目标函数
生成对抗网络的目标函数由生成器和判别器的损失函数构成:
判别器的损失函数: $$ \mathcal{L}D = -\mathbb{E}{x \sim p_{data}(x)} [\log D(x)] - \mathbb{E}_{z \sim p_z(z)} [\log(1 - D(G(z)))] $$
生成器的损失函数: $$ \mathcal{L}G = -\mathbb{E}{z \sim p_z(z)} [\log D(G(z))] $$
总体目标: $$ \min_G \max_D \mathbb{E}{x \sim p{data}(x)} [\log D(x)] + \mathbb{E}_{z \sim p_z(z)} [\log(1 - D(G(z)))] $$
# GAN结构示意图

这些是 GRU 网络、胶囊网络和生成对抗网络的主要思想及其计算过程和公式描述。希望这些解释能帮助你更好地理解这些深度学习模型。
# 三、计算题
算卷积

# 1. 计算模型的交叉熵损失
交叉熵损失函数的公式如下:
$$ L = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right] $$
其中,(y_i) 是第 (i) 个样本的真实标签,(p_i) 是第 (i) 个样本的预测概率,(N) 是样本总数。
给定真实标签 (y = [0, 1, 0, 0, 1]) 和预测概率 (p = [0.2, 0.8, 0.4, 0.1, 0.9]),我们计算每个样本的交叉熵损失并取平均值。
计算每个样本的损失:
(y_1 = 0, p_1 = 0.2) $$ L_1 = -(0 \log(0.2) + (1 - 0) \log(1 - 0.2)) = -\log(0.8) $$ 根据提示,($\log(2) \approx 0.301$),所以 $$ L_1 \approx -0.301 $$
(y_2 = 1, p_2 = 0.8) $$ L_2 = -(1 \log(0.8) + (1 - 1) \log(1 - 0.8)) = -\log(0.8) $$ $$ L_2 \approx -0.301 $$
(y_3 = 0, p_3 = 0.4) $$ L_3 = -(0 \log(0.4) + (1 - 0) \log(1 - 0.4)) = -\log(0.6) $$ 根据提示,($\log(3) \approx 0.477$),所以 $$ L_3 \approx -0.477 $$
(y_4 = 0, p_4 = 0.1) $$ L_4 = -(0 \log(0.1) + (1 - 0) \log(1 - 0.1)) = -\log(0.9) $$ $$ L_4 \approx -0.105 $$
(y_5 = 1, p_5 = 0.9) $$ L_5 = -(1 \log(0.9) + (1 - 1) \log(1 - 0.9)) = -\log(0.9) $$ $$ L_5 \approx -0.105 $$
求平均交叉熵损失: $$ L = \frac{1}{5} (L_1 + L_2 + L_3 + L_4 + L_5) \approx \frac{1}{5} (-0.301 - 0.301 - 0.477 - 0.105 - 0.105) = \frac{-1.289}{5} \approx -0.258 $$
# 2. 计算模型的焦点损失(Focal Loss)
焦点损失的公式如下:
$$ FL(p_t) = -\alpha (1 - p_t)^\gamma \log(p_t) $$
其中,(p_t) 是对第 (i) 个样本的预测概率,对于正样本(真实标签为1),(p_t = p_i);对于负样本(真实标签为0),(p_t = 1 - p_i)。
给定参数 ($\gamma = 2$) 和 ($\alpha = 0.4$),计算每个样本的焦点损失:
(y_1 = 0, p_1 = 0.2) $$ FL_1 = -0.4 (1 - 0.8)^2 \log(0.8) = -0.4 \cdot 0.04 \cdot -0.301 \approx 0.0048 $$
(y_2 = 1, p_2 = 0.8) $$ FL_2 = -0.4 (1 - 0.8)^2 \log(0.8) = -0.4 \cdot 0.04 \cdot -0.301 \approx 0.0048 $$
(y_3 = 0, p_3 = 0.4) $$ FL_3 = -0.4 (1 - 0.6)^2 \log(0.6) = -0.4 \cdot 0.16 \cdot -0.477 \approx 0.0305 $$
(y_4 = 0, p_4 = 0.1) $$ FL_4 = -0.4 (1 - 0.9)^2 \log(0.9) = -0.4 \cdot 0.01 \cdot -0.105 \approx 0.00042 $$
(y_5 = 1, p_5 = 0.9) $$ FL_5 = -0.4 (1 - 0.9)^2 \log(0.9) = -0.4 \cdot 0.01 \cdot -0.105 \approx 0.00042 $$
求平均焦点损失: $$ FL = \frac{1}{5} (FL_1 + FL_2 + FL_3 + FL_4 + FL_5) \approx \frac{1}{5} (0.0048 + 0.0048 + 0.0305 + 0.00042 + 0.00042) = \frac{0.041}{5} \approx 0.0082 $$
总结:
- 交叉熵损失约为 (-0.258)。
- 焦点损失约为 (0.0082)。